MaybeShewill-CV/CRNN_Tensorflow
A 2015 OCR paper, still running on TensorFlow 1.15
A faithful TensorFlow implementation of CRNN for scene text recognition, with pretrained weights for English and Chinese.
Not currently ranked — collecting fresh signals.
star history
What it does
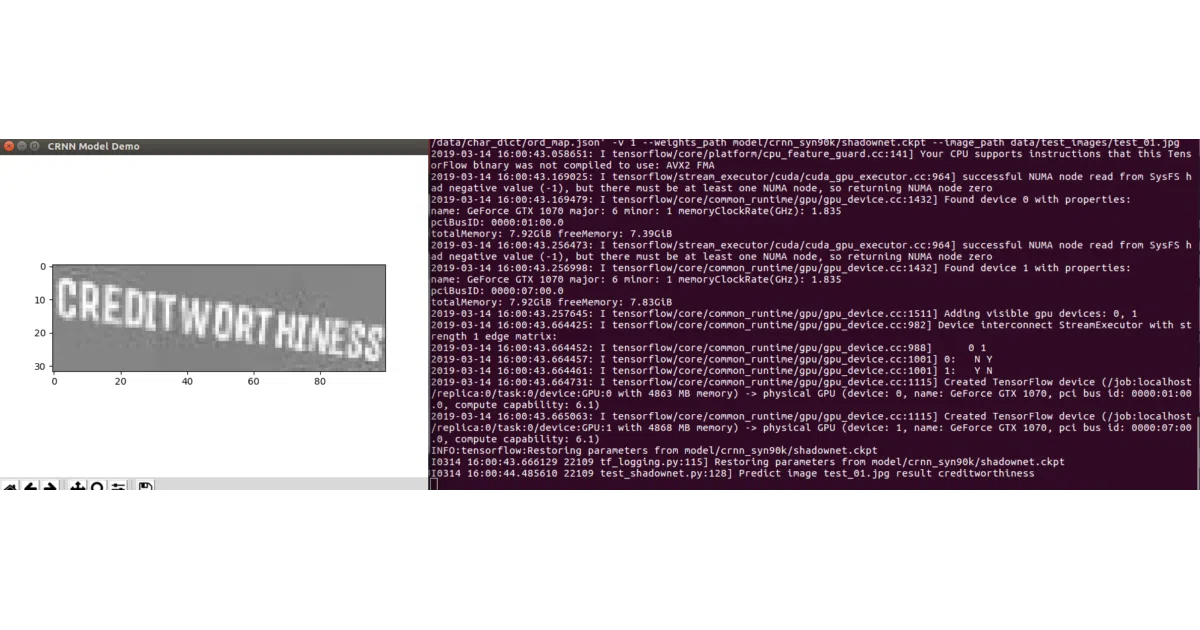
This repo implements the classic CRNN architecture from Shi et al.’s 2015 paper: convolutional features fed into a Bi-LSTM, trained end-to-end with CTC loss. It reads text in the wild—street signs, scanned documents, whatever you throw at it—and spits out character sequences without needing per-character alignment in the training data.
The interesting bit
The author didn’t just port the paper; they trained and released two full sets of weights: one on Synth90k (English synthetic text) and a separate Chinese model on an unnamed 2.7-million-image dataset with 5,824 character classes. There’s even a small PDF recognition demo. Plus TensorFlow Serving export scripts, which you don’t see in every research repo from 2017.
Key highlights
- Pretrained English model: 97.4% per-character precision, 93.3% full-sequence accuracy on 891k Synth90k test images
- Pretrained Chinese model with 5,824 classes, sequence length 70, image size 280×32
- Multi-GPU training support via
--multi_gpus 1 - TensorFlow Serving integration with both REST and gRPC client examples
- Training resumption from snapshots; optional decoded output metrics (slower but informative)
Caveats
- Locked to TensorFlow 1.15 and Python 3.5; the README explicitly warns about incompatibility with newer versions
- The Chinese dataset source is unattributed—the author admits they don’t know who owns it
- No online demo yet; TODO has been unchecked for years
Verdict
Worth a look if you need a battle-tested CRNN baseline or Chinese OCR weights and can tolerate legacy TensorFlow. Skip it if you want modern TF2/PyTorch or a maintained, production-ready pipeline.
Frequently asked
- What is MaybeShewill-CV/CRNN_Tensorflow?
- A faithful TensorFlow implementation of CRNN for scene text recognition, with pretrained weights for English and Chinese.
- Is CRNN_Tensorflow open source?
- Yes — MaybeShewill-CV/CRNN_Tensorflow is open source, released under the MIT license.
- What language is CRNN_Tensorflow written in?
- MaybeShewill-CV/CRNN_Tensorflow is primarily written in Python.
- How popular is CRNN_Tensorflow?
- MaybeShewill-CV/CRNN_Tensorflow has 1k stars on GitHub.
- Where can I find CRNN_Tensorflow?
- MaybeShewill-CV/CRNN_Tensorflow is on GitHub at https://github.com/MaybeShewill-CV/CRNN_Tensorflow.