MIC-DKFZ/medicaldetectiontoolkit
Medical object detection that speaks 3D and handles messy labels
A PyTorch framework that extends standard detectors to volumetric medical images and lets you train with pixel-wise or bounding-box annotations interchangeably.
Not currently ranked — collecting fresh signals.
star history
What it does This toolkit wraps 2D and 3D implementations of Mask R-CNN, RetinaNet, and friends into a training and inference system built for medical imaging. It handles the tedious parts: dynamic patching and tiling of large volumetric scans, test-time ensembling, and a custom “weighted box clustering” algorithm that merges overlapping predictions across patches and augmentations. It also integrates the MIC-DKFZ batch generators for data augmentation and tracks COCO-style mAP metrics.
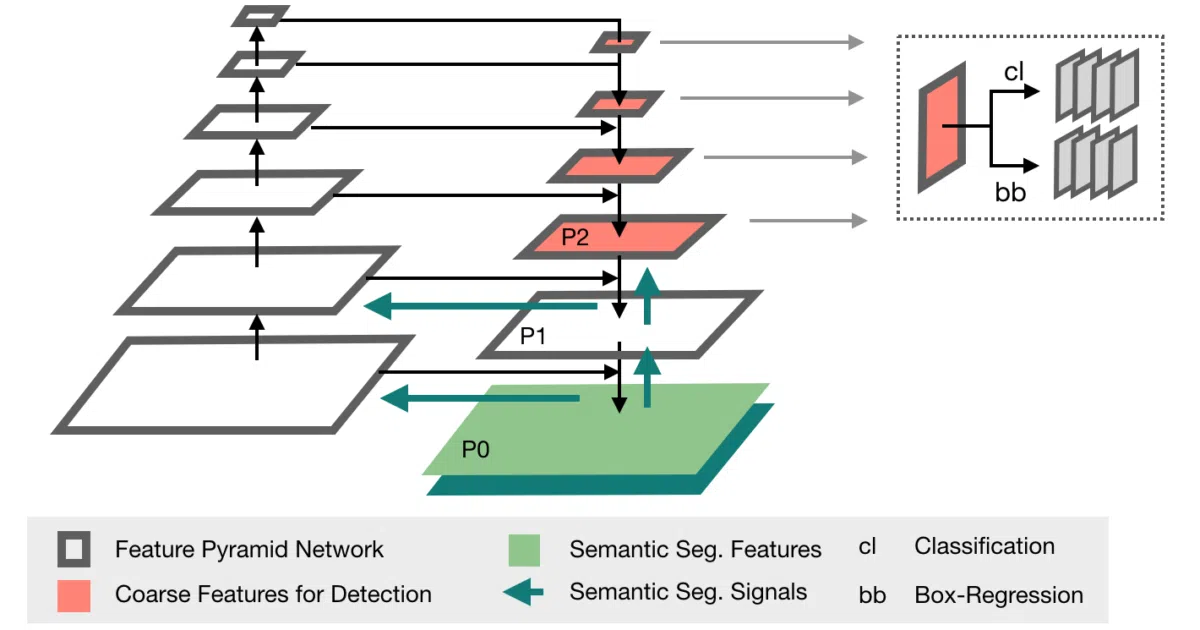
The interesting bit The standout is Retina U-Net, the authors’ own architecture that fuses a U-Net segmentation backbone with object detection heads—plus a clever trick where segmentation masks are fed through data augmentation and boxes are redrawn afterwards, so you can train with pixel labels, box labels, or both without coordinate corruption.
Key highlights
- 2D and 3D variants of Mask R-CNN, RetinaNet, Retina U-Net, Faster R-CNN+, U-Faster R-CNN+, and DetU-Net in one modular codebase
- Handles both labeled-region-of-interest maps and plain binary masks (with connected-component labeling on the fly)
- Automatic patching, tiling, ensembling, and weighted consolidation of predictions for inference on large images
- Built-in visualization: loss curves, prediction histograms, and overlay plots of inputs/ground truth/outputs per epoch
- 5-fold cross-validation support with configurable splits
Caveats
- No longer maintained — the authors explicitly point to nnDetection as the successor
- CUDA kernels for NMS and RoIAlign ship precompiled for TitanX only; other GPUs require manual
nvccrecompilation with the correctsm_arch flag - Python 3.6 virtualenv in the install instructions dates the project
- Data loaders are described as “examples” meant to be customized, not drop-in solutions
Verdict Worth studying if you’re building medical detection pipelines and want to see how standard vision architectures adapt to 3D volumes and weak label formats. Skip it for new projects and use nnDetection instead, unless you need to reproduce the Retina U-Net paper specifically.
Frequently asked
- What is MIC-DKFZ/medicaldetectiontoolkit?
- A PyTorch framework that extends standard detectors to volumetric medical images and lets you train with pixel-wise or bounding-box annotations interchangeably.
- Is medicaldetectiontoolkit open source?
- Yes — MIC-DKFZ/medicaldetectiontoolkit is open source, released under the Apache-2.0 license.
- What language is medicaldetectiontoolkit written in?
- MIC-DKFZ/medicaldetectiontoolkit is primarily written in Python.
- How popular is medicaldetectiontoolkit?
- MIC-DKFZ/medicaldetectiontoolkit has 1.4k stars on GitHub.
- Where can I find medicaldetectiontoolkit?
- MIC-DKFZ/medicaldetectiontoolkit is on GitHub at https://github.com/MIC-DKFZ/medicaldetectiontoolkit.