LLaVA-VL/LLaVA-Plus-Codebase
LLaVA with a toolbox: learning to call vision tools
LLaVA-Plus extends a multimodal chatbot with pluggable computer vision tools so it can ground, segment, or recognize instead of bluffing through image tasks.
Not currently ranked — collecting fresh signals.
star history
What it does
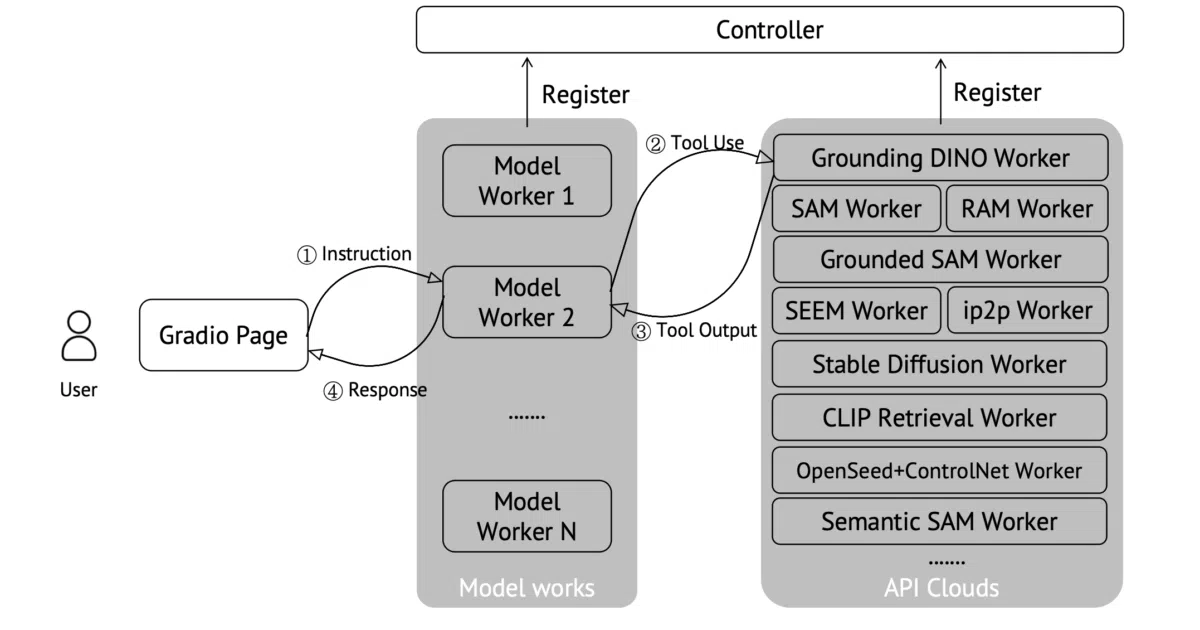
LLaVA-Plus extends the LLaVA vision-language model with a tool-use layer. It learns to hand off specialized vision tasks—segmentation, grounding, recognition—to dedicated external models instead of answering from frozen weights alone. A controller routes traffic between a central model worker and pluggable tool workers.
The interesting bit
Tool use is treated as a learned skill, not a hardcoded pipeline. Through tool-augmented visual instruction tuning on datasets like COCO and Visual Genome, the model decides which computer-vision worker to invoke for a given image query. It is largely glue code, but the glue is trained.
Key highlights
- Modular architecture with separate controller, model worker, and standalone tool workers
- Integrates existing vision models such as SAM, Grounding DINO, SEEM, and Recognize Anything as callable skills
- Training recipe relies on tool-annotated data from COCO, Visual Genome, InfoSeek, and HierText
- Requires substantial compute: training targets 4–8 A100 80GB GPUs
- Research-only license (CC BY-NC 4.0); commercial use is explicitly restricted
Caveats
- Authors state that portions of the code and model weights are still being prepared and not yet released
- Running the demo requires manually orchestrating a controller, model worker, individual tool workers, and a Gradio server
Verdict
A useful reference if you are building tool-augmented multimodal agents or wiring LLMs into CV pipelines. Avoid if you need a production-ready product; the repo is partially incomplete and the license forbids commercial deployment.
Frequently asked
- What is LLaVA-VL/LLaVA-Plus-Codebase?
- LLaVA-Plus extends a multimodal chatbot with pluggable computer vision tools so it can ground, segment, or recognize instead of bluffing through image tasks.
- Is LLaVA-Plus-Codebase open source?
- Yes — LLaVA-VL/LLaVA-Plus-Codebase is open source, released under the Apache-2.0 license.
- What language is LLaVA-Plus-Codebase written in?
- LLaVA-VL/LLaVA-Plus-Codebase is primarily written in Python.
- How popular is LLaVA-Plus-Codebase?
- LLaVA-VL/LLaVA-Plus-Codebase has 770 stars on GitHub.
- Where can I find LLaVA-Plus-Codebase?
- LLaVA-VL/LLaVA-Plus-Codebase is on GitHub at https://github.com/LLaVA-VL/LLaVA-Plus-Codebase.