Ki6an/fastT5
T5 inference that won't make you wait for coffee
A Python library that exports, quantizes, and ONNX-ifies T5 models so your CPU can finally catch its breath.
Not currently ranked — collecting fresh signals.
star history
What it does
fastT5 takes any pretrained HuggingFace T5 model, exports it to ONNX, quantizes it down to 8-bit, and wraps it in an ONNX Runtime session. The returned object still speaks HuggingFace’s generate() API, so your calling code barely changes. One-liner convenience or step-by-step pipeline, your choice.
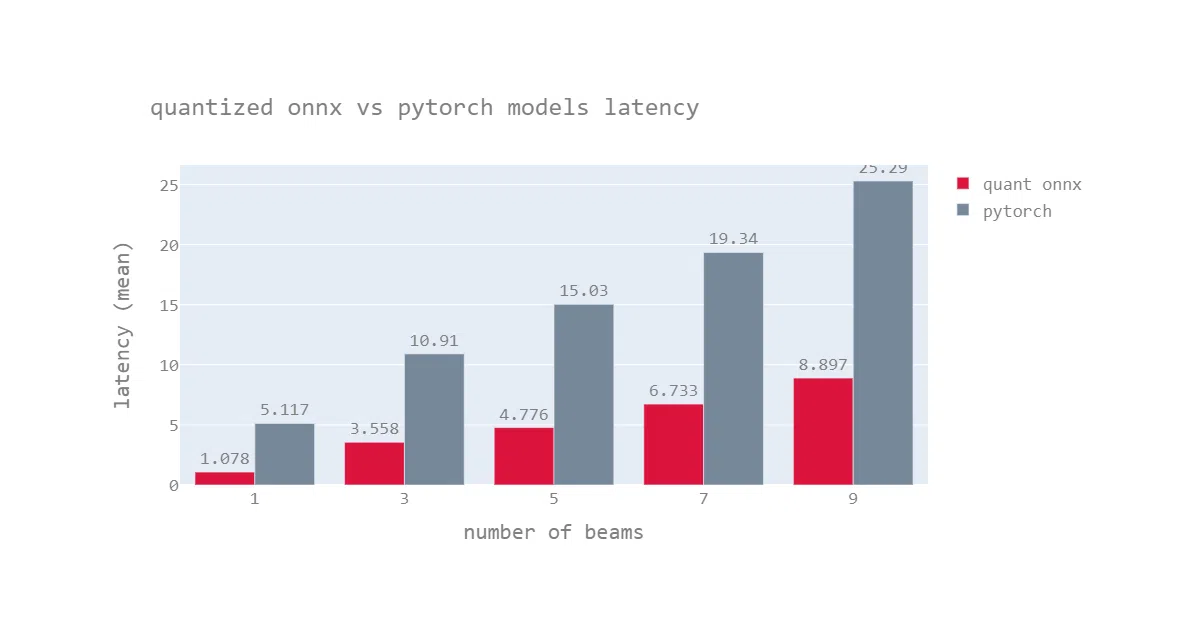
The interesting bit
T5’s encoder-decoder architecture and variable-length past_key_values make it a pain to ONNX-export cleanly. The workaround: split the decoder into two ONNX graphs—one for the first step without cached states, one for subsequent steps with them. That trick, plus quantization, is where the 3× size reduction and claimed 5× speedup come from.
Key highlights
- Single-call export:
export_and_get_onnx_model("t5-small")handles conversion, quantization, and runtime setup - Benchmarks (T5-base, English→French, AMD EPYC 7B12 CPU): ~5.7× faster for greedy search, 3–4× for beam search vs. PyTorch
- Quantized models trade a sliver of BLEU/ROUGE for the speed—scores are within ~1–5% of original per the provided tables
- Supports private HuggingFace Hub models via token authentication
- Custom output paths for caching exported models between runs
Caveats
- CPU-only for now; GPU support is listed as not yet implemented
- Speed gains taper off for longer sequence lengths (visible in the benchmark heatmaps)
- Results were generated on a specific server-grade CPU; your laptop may differ
Verdict Worth a look if you’re running T5 inference on CPU and need to cut latency without rewriting your pipeline. Skip it if you’re already GPU-bound or need the absolute best accuracy—quantization isn’t free.
Frequently asked
- What is Ki6an/fastT5?
- A Python library that exports, quantizes, and ONNX-ifies T5 models so your CPU can finally catch its breath.
- Is fastT5 open source?
- Yes — Ki6an/fastT5 is open source, released under the Apache-2.0 license.
- What language is fastT5 written in?
- Ki6an/fastT5 is primarily written in Python.
- How popular is fastT5?
- Ki6an/fastT5 has 588 stars on GitHub.
- Where can I find fastT5?
- Ki6an/fastT5 is on GitHub at https://github.com/Ki6an/fastT5.