KellerJordan/modded-nanogpt
Training GPT-2 in 90 seconds: a speedrun in algorithmic overclocking
A collaborative race to see how fast 8 H100s can hit a fixed loss target on FineWeb, and the answer keeps getting shorter.
Not currently ranked — collecting fresh signals.
star history
What it does
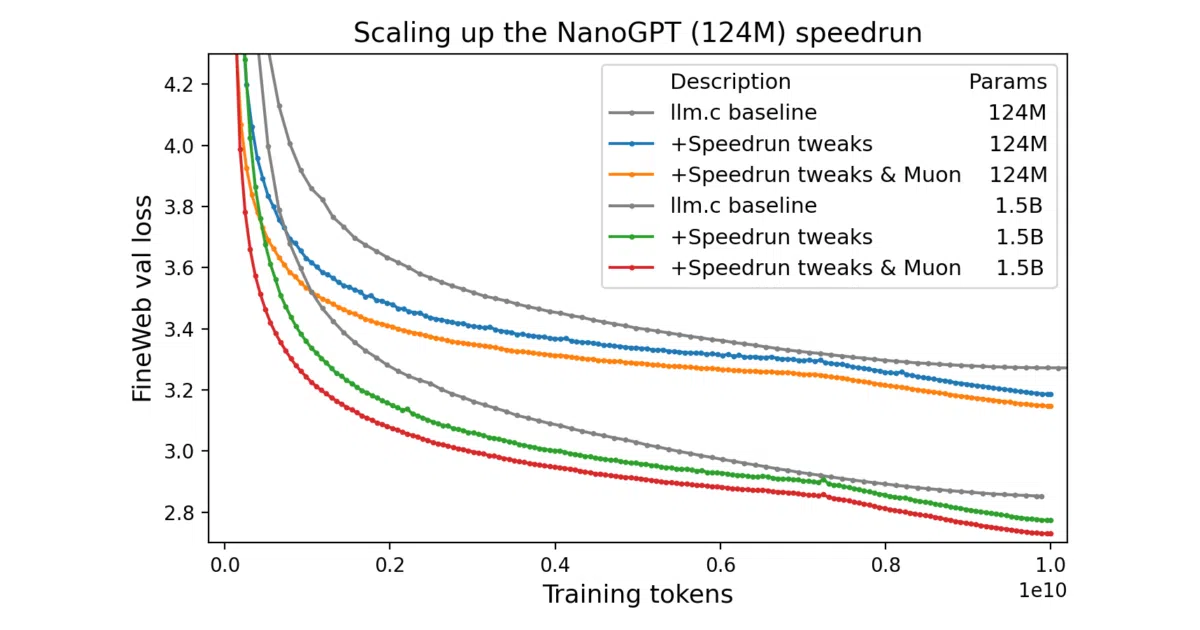
This repo tracks the NanoGPT speedrun, an open competition to train a 124M-parameter language model to ≤3.28 cross-entropy loss on FineWeb using exactly 8 NVIDIA H100 GPUs. The target itself is borrowed from Andrej Karpathy’s llm.c GPT-2 replication, which originally needed 45 minutes and 10 billion tokens. The current record: under 90 seconds and under 400 million tokens.
The interesting bit
The speedup isn’t from one big breakthrough but from dozens of small, often weird optimizations stacked together — a kind of algorithmic katamari. The Muon optimizer (a custom second-order method) is a major piece, but so are things like “Smear module to enable 1 token look back,” “Polar Express implementation in Muon,” and untying the embedding and LM head at exactly two-thirds of training. It’s less “better architecture” and more “discovering which 30 micro-optimizations compose without exploding.”
Key highlights
- 30× wall-clock speedup over the llm.c baseline (45 min → 90 sec)
- 25× data efficiency (10B tokens → <400M)
- Uses FP8 matmul, Flash Attention 3, and a long-short sliding window pattern inspired by Gemma 2
- Includes a secondary “optimization track” that minimizes steps with unlimited wall-clock time
- Full record history with dated logs and contributor attribution back to May 2024
Caveats
- Requires 8× H100s; the hardware floor is non-negotiable
- First
torch.compilerun adds ~7 minutes of warmup latency, so your first attempt won’t be sub-90-seconds - The README’s technique list is long and growing; which ones are load-bearing versus marginal is unclear
Verdict
Worth studying if you’re training small LLMs and want to see where the floor actually is — or if you enjoy the spectacle of competitive systems optimization. Not directly useful if you need a general-purpose trainer or lack the GPU budget.
Frequently asked
- What is KellerJordan/modded-nanogpt?
- A collaborative race to see how fast 8 H100s can hit a fixed loss target on FineWeb, and the answer keeps getting shorter.
- Is modded-nanogpt open source?
- Yes — KellerJordan/modded-nanogpt is open source, released under the MIT license.
- What language is modded-nanogpt written in?
- KellerJordan/modded-nanogpt is primarily written in Python.
- How popular is modded-nanogpt?
- KellerJordan/modded-nanogpt has 5.5k stars on GitHub.
- Where can I find modded-nanogpt?
- KellerJordan/modded-nanogpt is on GitHub at https://github.com/KellerJordan/modded-nanogpt.