IDEA-Research/Rex-Omni
One 3B model, eight vision tasks, zero specialist heads
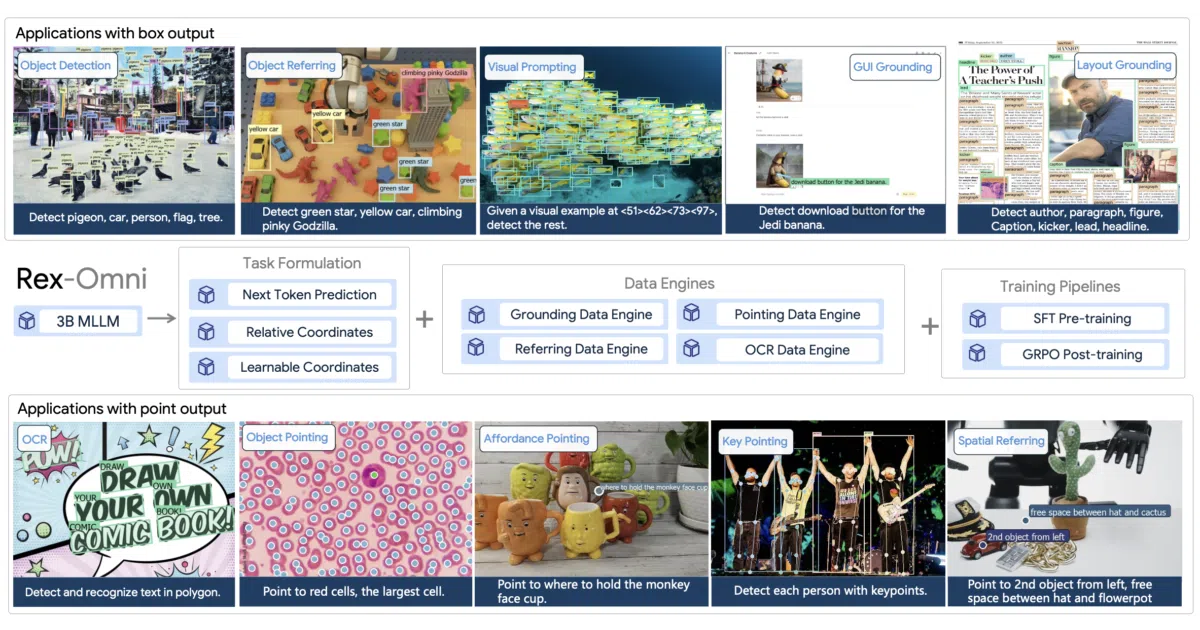
Rex-Omni treats bounding boxes, keypoints, OCR polygons, and GUI grounding as plain next-token prediction.
Not currently ranked — collecting fresh signals.
star history
What it does Rex-Omni is a 3B-parameter multimodal LLM that handles object detection, pointing, visual prompting, keypoint detection, OCR boxes/polygons, and GUI grounding through a single text-generation interface. You pass an image and a task name; the model emits structured coordinates as raw tokens, which the wrapper parses into boxes, points, or polygons. It runs via Transformers or vLLM, with an AWQ-quantized variant that halves storage.
The interesting bit Instead of bolting detection heads onto a vision backbone, the authors flattened every spatial task into autoregressive token prediction. The model literally types out coordinates. That unification means you can fine-tune on custom pointing datasets with standard SFT or GRPO—no architecture surgery required.
Key highlights
- Eight tasks in one model: detection, pointing, visual prompting, keypointing, OCR (box & polygon), GUI grounding, GUI pointing
- 3B parameters; AWQ quantization available for leaner deployment
- Supports both Hugging Face Transformers and vLLM backends
- Fine-tuning code and evaluation benchmarks released; cookbooks include Python scripts and Jupyter notebooks for every task
- Structured outputs parsed automatically; raw LLM text plus extracted predictions returned per image
Caveats
- The README claims “Detect Anything” but does not list training data, zero-shot benchmarks, or comparison numbers against specialist models
- Several tutorial filenames contain typos (
layout_grouding_examle.py,rex.inferenceparameter docs with a stray quote inkeypoint_type"), suggesting the project is fresh and documentation is still settling
Verdict Worth a look if you want one lightweight model for heterogeneous vision tasks and prefer prompt engineering to maintaining a zoo of detectors. Skip it if you need proven SOTA accuracy on a single task or rigorous benchmark transparency.
Frequently asked
- What is IDEA-Research/Rex-Omni?
- Rex-Omni treats bounding boxes, keypoints, OCR polygons, and GUI grounding as plain next-token prediction.
- Is Rex-Omni open source?
- Yes — IDEA-Research/Rex-Omni is an open-source project tracked on heatdrop.
- What language is Rex-Omni written in?
- IDEA-Research/Rex-Omni is primarily written in Jupyter Notebook.
- How popular is Rex-Omni?
- IDEA-Research/Rex-Omni has 1.5k stars on GitHub.
- Where can I find Rex-Omni?
- IDEA-Research/Rex-Omni is on GitHub at https://github.com/IDEA-Research/Rex-Omni.