ICT-BDA/EasyML
A drag-and-drop Spark pipeline from a 2016 paper
EasyML wraps Hadoop and Spark jobs in a visual DAG editor so teams can stitch together ML workflows without writing boilerplate.
Not currently ranked — collecting fresh signals.
star history
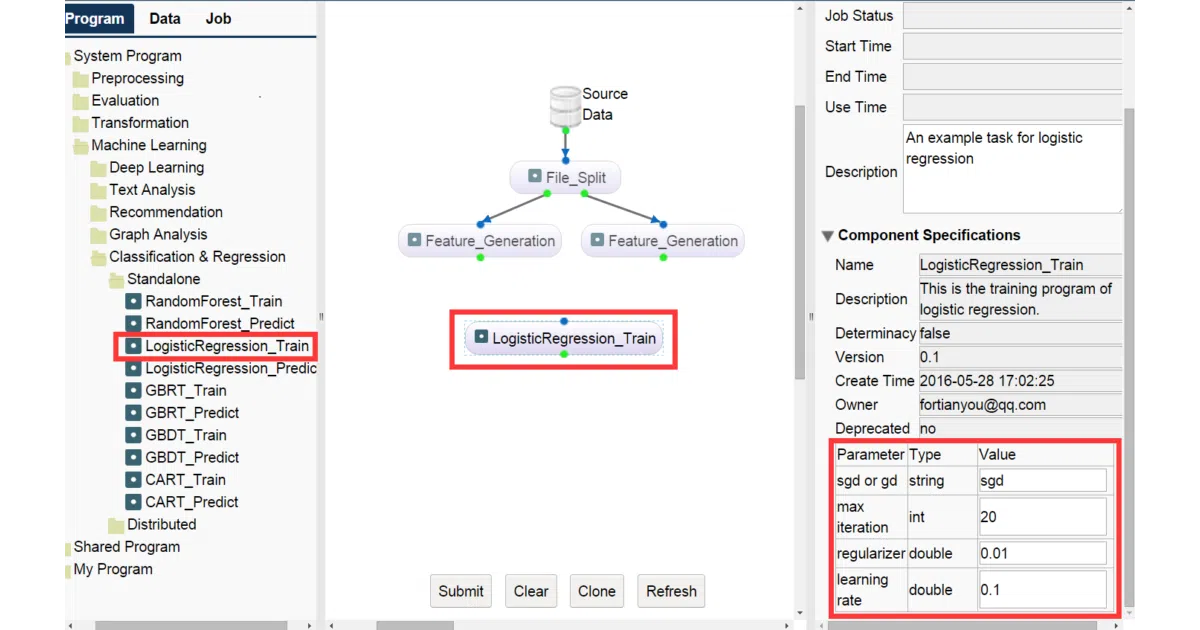
What it does EasyML is a Java-based visual studio for building machine learning workflows as directed acyclic graphs. You drag algorithms and datasets onto a canvas, wire them together, and submit the resulting DAG to a Docker-based cluster running Hadoop and Spark. The system handles scheduling, re-runs only changed nodes on resubmission, and lets you preview outputs and logs by right-clicking.
The interesting bit The project treats “seamless” integration of stand-alone Linux programs and distributed Spark/MapReduce jobs as its core trick—one DAG can mix both without the user caring about the backend. It also caches intermediate outputs so iterative experimentation doesn’t recompute the entire pipeline.
Key highlights
- Visual DAG editor with cloneable task templates
- Mixed execution: single-node Linux binaries alongside Spark and MapReduce jobs
- Incremental re-execution on modified DAGs
- Built-in algorithm library covering preprocessing, feature generation, and evaluation
- Docker-based cluster deployment with a live demo server (status unclear)
Caveats
- The README contains broken image tags and typos (“we organised a cluster of server on Docker”)
- Last major publication was 2017; the demo URLs may be stale
- Default credentials (
bdaict@hotmail.com/bdaict) are hardcoded in the docs
Verdict Worth a look if you’re maintaining legacy Spark/Hadoop infrastructure and need a GUI for non-coders. Skip it if you’re already on modern orchestration (Airflow, Kubeflow, etc.) or want active development.
Frequently asked
- What is ICT-BDA/EasyML?
- EasyML wraps Hadoop and Spark jobs in a visual DAG editor so teams can stitch together ML workflows without writing boilerplate.
- Is EasyML open source?
- Yes — ICT-BDA/EasyML is open source, released under the Apache-2.0 license.
- What language is EasyML written in?
- ICT-BDA/EasyML is primarily written in Java.
- How popular is EasyML?
- ICT-BDA/EasyML has 2k stars on GitHub.
- Where can I find EasyML?
- ICT-BDA/EasyML is on GitHub at https://github.com/ICT-BDA/EasyML.