Hironsan/anago
Keras NER without the linguistic plumbing
A Keras library that treats named-entity recognition as a generic sequence-labeling problem, no language-specific feature engineering required.
Not currently ranked — collecting fresh signals.
star history
What it does
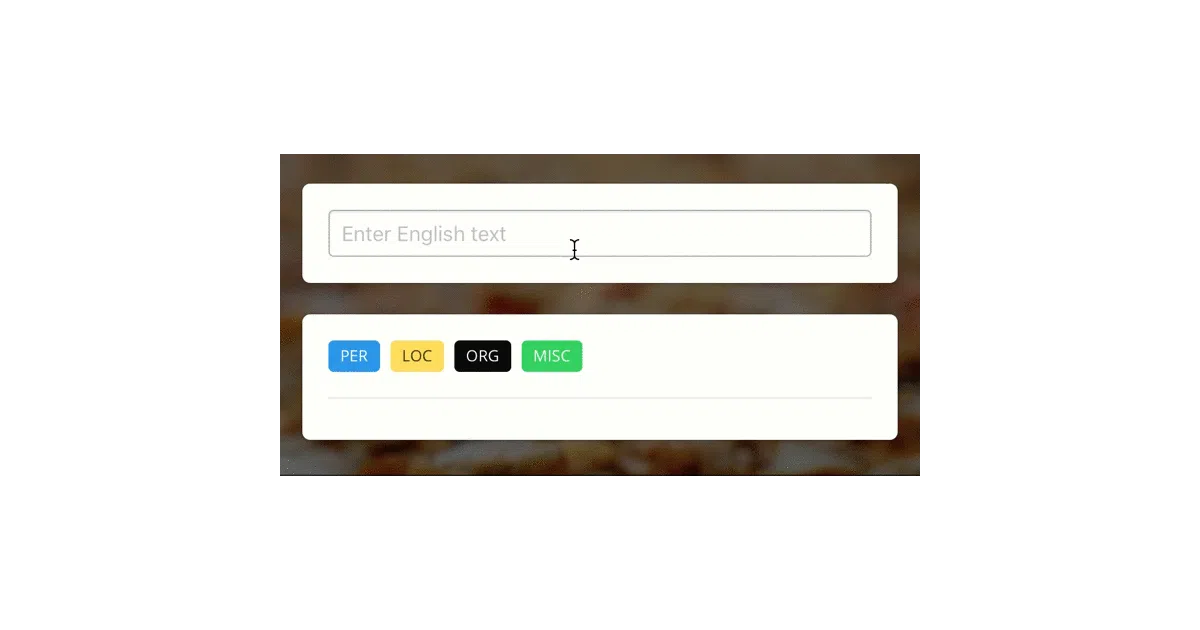
anaGo wraps BiLSTM-CRF and ELMo models into a scikit-learn-ish API: fit, score, analyze, save/load. Feed it tokenized sentences and IOB-style labels; it handles the rest. The library targets NER, part-of-speech tagging, and similar sequence-labeling tasks across any language.
The interesting bit
The pitch is “no language dependent features” — you don’t hand-craft POS tags or morphological rules. The ELMo path (F1 92.22) is more involved than the basic Sequence model, but the README at least points you to the right modules and an example script rather than leaving you to reverse-engineer the architecture.
Key highlights
anago.Sequence()gets you training and tagging in a few lines- Pre-trained CoNLL-2003 English model available via
download() - Character-level features and CRF layer included in the base stack
- ELMo support via
ELModel/ELMoTransformerfor higher scores - GPU support and custom callback hooks
Caveats
- Officially supports Python 3.4–3.6 only; unclear if it runs cleanly on modern Python
- Documentation is marked “(coming soon)” — the README and code examples are your docs
- The basic model hits 0.802 F1 out of the box; you need pre-trained embeddings (or ELMo) to approach the advertised 90.94+ scores
Verdict
Worth a look if you want a quick Keras-native NER baseline without SpaCy or Hugging Face overhead. Skip it if you need production maintenance or modern Python support; the repo hasn’t kept pace with the ecosystem.
Frequently asked
- What is Hironsan/anago?
- A Keras library that treats named-entity recognition as a generic sequence-labeling problem, no language-specific feature engineering required.
- Is anago open source?
- Yes — Hironsan/anago is open source, released under the MIT license.
- What language is anago written in?
- Hironsan/anago is primarily written in Python.
- How popular is anago?
- Hironsan/anago has 1.5k stars on GitHub.
- Where can I find anago?
- Hironsan/anago is on GitHub at https://github.com/Hironsan/anago.