HKUDS/RAG-Anything
RAG that reads the diagrams, not just the text
Most RAG systems treat PDFs as flat text; RAG-Anything parses them into text, images, tables, and equations so you can query the whole page.
Velocity · 7d
+20
★ / day
Trend
↘cooling
star history
What it does
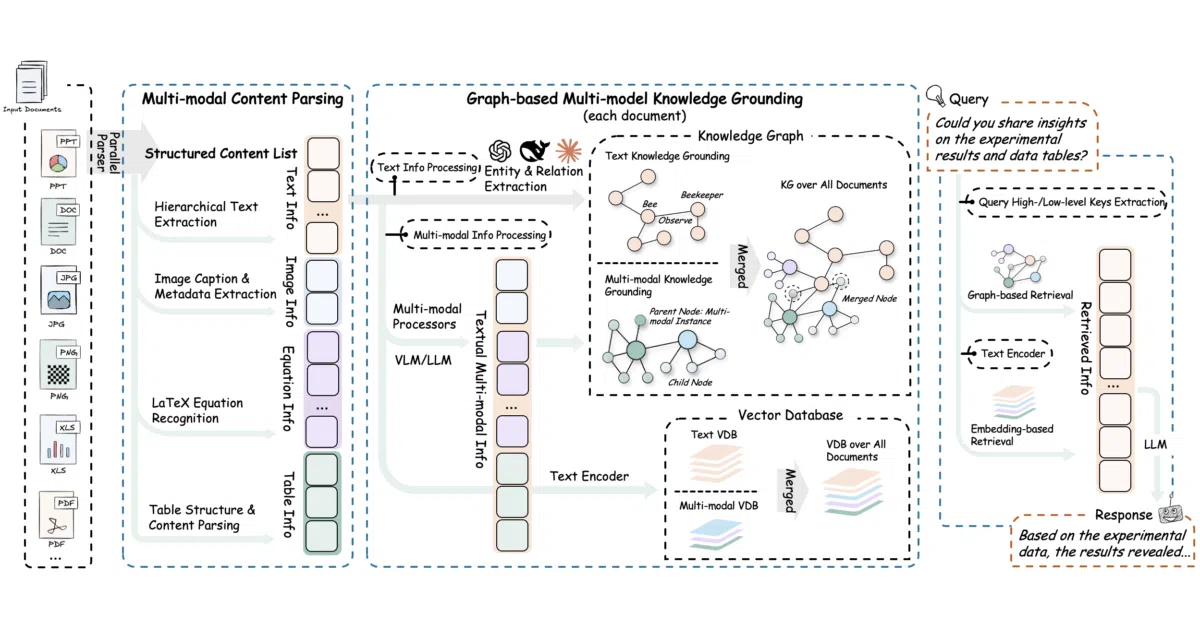
RAG-Anything is an orchestration layer atop LightRAG that turns mixed-content documents into queryable knowledge. It uses MinerU to decompose PDFs and Office files into text blocks, images, tables, and equations, then routes each modality through its own processing channel. The result is a unified retrieval interface where a query can pull from both the text and the visuals in a document.
The interesting bit
Rather than flattening a document into a single stream, the system preserves hierarchy and cross-modal relationships inside a multimodal knowledge graph. It also offers a bypass mode: if you already have pre-parsed content, you can inject it directly instead of re-parsing from scratch.
Key highlights
- Built on LightRAG with added multimodal routing and VLM-enhanced query support for image-heavy documents.
- Uses MinerU for layout-aware extraction across PDFs, DOCX, PPTX, XLSX, and images.
- Maintains a multimodal knowledge graph linking entities across text, tables, and visuals.
- Supports direct insertion of pre-parsed content lists to skip the parsing stage.
- Concurrent pipelines for text and multimodal content.
Caveats
- The README is heavy on marketing gradients and light on concrete technical specifics—backend model choices, latency numbers, and hardware requirements are not detailed in the visible text.
- It is fundamentally an integration framework; the core retrieval smarts remain in LightRAG and the parsing smarts in MinerU.
Verdict
Worth evaluating if you need multimodal RAG over complex documents and prefer a pre-wired stack over DIY plumbing. Skip it if you are looking for a novel retrieval algorithm or a lightweight, single-purpose library.
Frequently asked
- What is HKUDS/RAG-Anything?
- Most RAG systems treat PDFs as flat text; RAG-Anything parses them into text, images, tables, and equations so you can query the whole page.
- Is RAG-Anything open source?
- Yes — HKUDS/RAG-Anything is open source, released under the MIT license.
- What language is RAG-Anything written in?
- HKUDS/RAG-Anything is primarily written in Python.
- How popular is RAG-Anything?
- HKUDS/RAG-Anything has 22.4k stars on GitHub and is currently cooling off.
- Where can I find RAG-Anything?
- HKUDS/RAG-Anything is on GitHub at https://github.com/HKUDS/RAG-Anything.