EricSteinberger/PokerRL
A research lab for teaching AIs to bluff
PokerRL is a Python framework that wraps the messy plumbing of multi-agent deep RL so researchers can focus on making better poker bots instead of debugging distributed workers.
Not currently ranked — collecting fresh signals.
star history
What it does
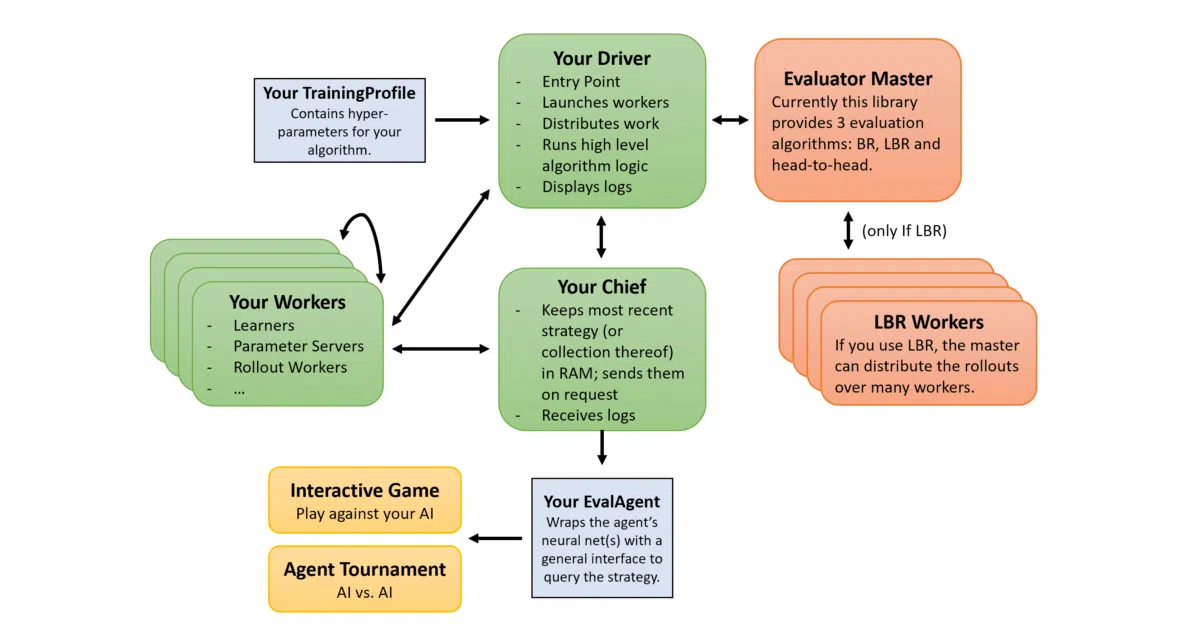
PokerRL provides a complete environment and training framework for poker-playing AI research. It bundles a game engine, several evaluation metrics (including exact best-response exploitability and approximate local BR), baseline implementations of CFR variants, and a Ray-based wrapper that lets the same code run locally or scale to a cluster. There’s even an InteractiveGame if you want to lose to your own creation.
The interesting bit The framework is explicitly designed around the recent shift from full game-tree traversal to sampling-based methods that only visit a fraction of states. It ships with ~4 lines of boilerplate to turn any local worker class into a distributed worker, which is the kind of abstraction that saves weeks when you’re iterating on something like Neural Fictitious Self-Play or Deep CFR.
Key highlights
- Built-in evaluation metrics: exact BR (small games), Local BR, RL-BR via DDQN, and head-to-head matches
- Baseline implementations of vanilla CFR, CFR+, and Linear CFR for comparison
- Ray integration for single-machine multi-core or multi-node cluster deployment
- Optional game-tree visualization tool for debugging strategies in tiny games
- C++ hand evaluator with Python bindings (binaries included for Windows/Linux)
Caveats
- Some components (like exact Best Response) only work for 2-player games
- Distributed mode requires Linux due to Ray limitations
- PyTorch 0.4.1 is pinned; the README notes 1.0 is slower for the recurrent networks used here
- Setup involves conda, Docker for PyCrayon/TensorBoard, and manual AWS security group configuration
Verdict Worth a look if you’re doing research on imperfect-information games or need a reproducible baseline for comparing new algorithms against CFR variants. Skip it if you just want to train a decent poker bot quickly—this is scaffolding for papers, not a pretrained model zoo.
Frequently asked
- What is EricSteinberger/PokerRL?
- PokerRL is a Python framework that wraps the messy plumbing of multi-agent deep RL so researchers can focus on making better poker bots instead of debugging distributed workers.
- Is PokerRL open source?
- Yes — EricSteinberger/PokerRL is open source, released under the MIT license.
- What language is PokerRL written in?
- EricSteinberger/PokerRL is primarily written in Python.
- How popular is PokerRL?
- EricSteinberger/PokerRL has 533 stars on GitHub.
- Where can I find PokerRL?
- EricSteinberger/PokerRL is on GitHub at https://github.com/EricSteinberger/PokerRL.