EdGENetworks/attention-networks-for-classification
Attention, but make it bureaucratic: a PyTorch doc classifier
A readable PyTorch re-implementation of the CMU hierarchical attention paper, with honest notes on where it falls short.
Not currently ranked — collecting fresh signals.
star history
What it does
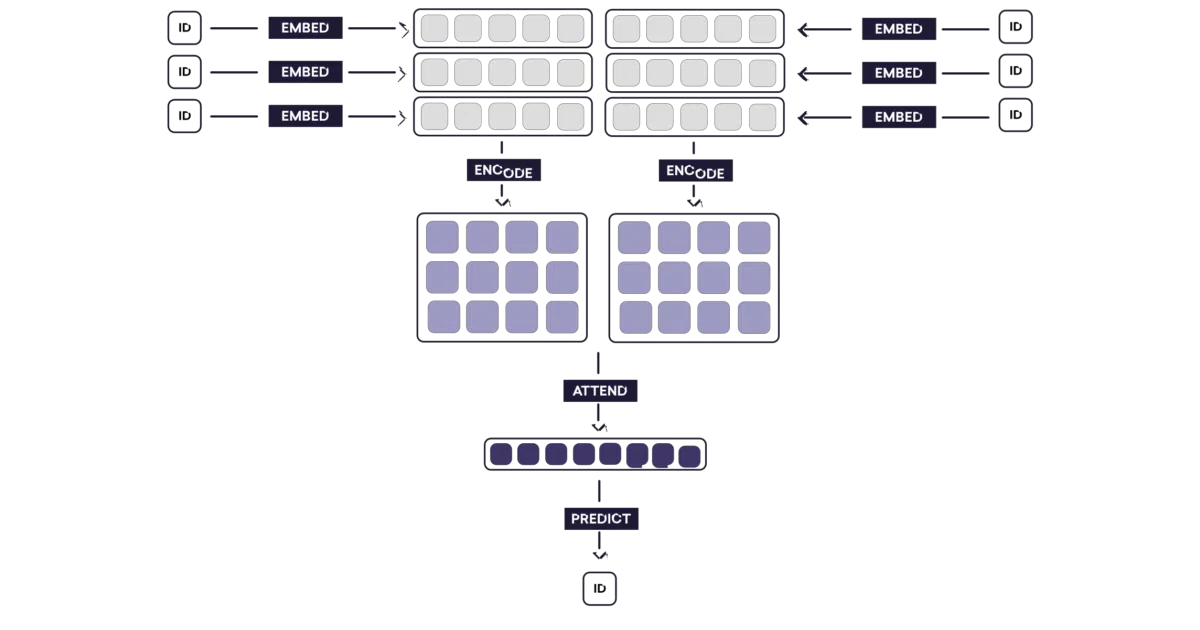
This repo implements a neural document classifier that pays attention twice: once to pick important words in each sentence, again to pick important sentences in the document. It’s a PyTorch port of Yang et al.’s NAACL 2016 paper, applied to the IMDB movie review dataset.
The interesting bit
The author is admirably frank. They note they jointly optimize word- and sentence-level attention with one optimizer (the paper used two), admit their padding strategy is inefficient, and report a best accuracy of ~0.35 on a 10-class subset—well below what you’d hope. The struck-through note about PyTorch’s missing mask support, updated when pack_padded_sequence arrived, is a small time capsule of 2017 framework churn.
Key highlights
- Clean hierarchical attention architecture: word → sentence → document
- Bidirectional GRU at both levels with attention weights
- Preprocessed IMDB data provided via Google Drive link
- Training loss curve included for reproducibility
- Acknowledges divergence from paper: single optimizer, padded minibatches
Caveats
- ~35% accuracy on 10-class IMDB is quite poor; the author doesn’t explain why (data mismatch? hyperparameters?)
- Uses a substitute dataset (84,919 samples) because the original paper’s IMDB split wasn’t available
- No code structure beyond a single notebook; not packaged for reuse
Verdict
Worth a skim if you’re learning attention mechanisms and want to see the concept in readable PyTorch. Skip it if you need a production document classifier or a faithful reproduction of the paper’s reported results.
Frequently asked
- What is EdGENetworks/attention-networks-for-classification?
- A readable PyTorch re-implementation of the CMU hierarchical attention paper, with honest notes on where it falls short.
- Is attention-networks-for-classification open source?
- Yes — EdGENetworks/attention-networks-for-classification is an open-source project tracked on heatdrop.
- What language is attention-networks-for-classification written in?
- EdGENetworks/attention-networks-for-classification is primarily written in Jupyter Notebook.
- How popular is attention-networks-for-classification?
- EdGENetworks/attention-networks-for-classification has 606 stars on GitHub.
- Where can I find attention-networks-for-classification?
- EdGENetworks/attention-networks-for-classification is on GitHub at https://github.com/EdGENetworks/attention-networks-for-classification.