DagnyT/hardnet
A local descriptor that learned to stop chasing easy wins
HardNet trains image patch descriptors by deliberately mining the hardest negatives, not the closest misses.
Not currently ranked — collecting fresh signals.
star history
What it does
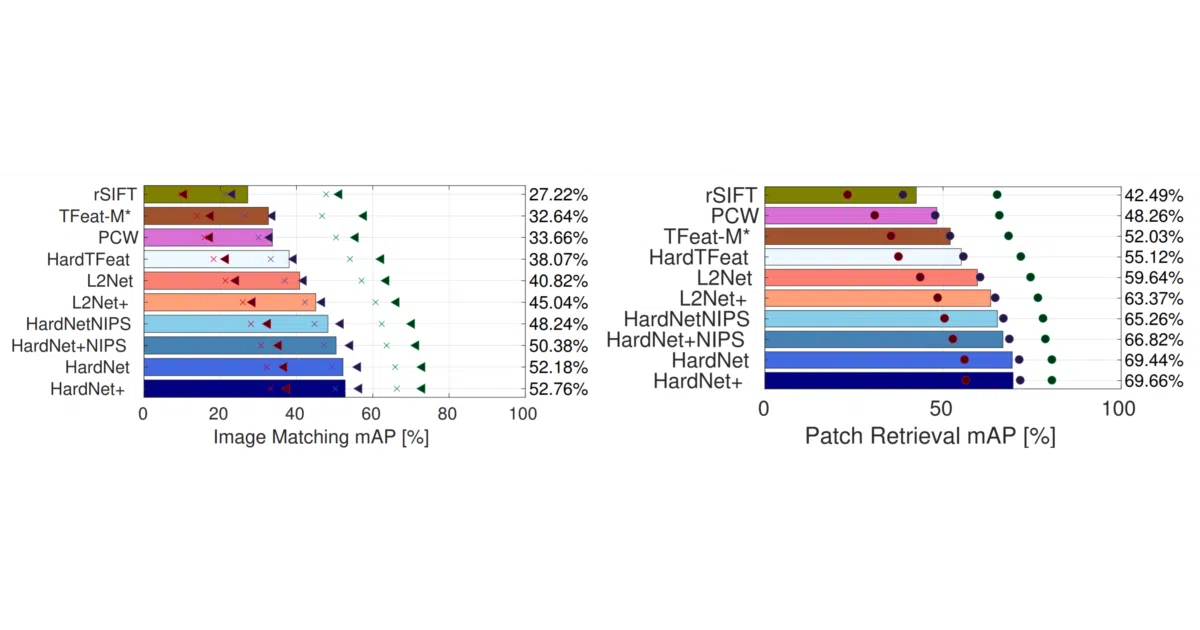
HardNet is a CNN that turns small grayscale image patches into 128-D descriptors for matching—think SIFT, but learned. It was introduced at NeurIPS 2017 and this repo holds the PyTorch implementation, pre-trained weights, and a TorchScript export example. The training code targets the Brown PhotoTour dataset (now mirrored from CTU Prague since the original links died in April 2025).
The interesting bit
The loss function is the star: instead of standard triplet loss with semi-hard mining, HardNet uses a “hardest-in-batch” strategy that optimizes the distance between the closest negative and the anchor. The paper’s title is not a joke—it literally works hard to know its neighbor’s margins. The README also notes a small but meaningful trick: adding shift and rotation augmentation during training bumps HPatches mAP by roughly a point.
Key highlights
- Pre-trained HardNet++ weights recommended for practical use; HardNetLib+ for fair comparisons against Liberty-trained baselines
- Third-party HardNetPS weights (Mitra et al.) trained on a larger patch dataset, available in converted PyTorch format
- Includes Caffe and PyTorch inference examples for HPatches-format patch files
- TorchScript conversion notebook for C++ deployment
- Companion work: AffNet, a learned affine shape estimator that pairs with HardNet++ to hit 89.5 mAP on Oxford5k with HQE+MA
Caveats
- Python 2.7 listed in requirements; some modernization likely needed for current environments
- The BoW retrieval engine used in Oxford5k benchmarks is proprietary and not included—README points to ASMK, HQE, and VISE as open alternatives
- PhotoTour dataset availability has been fragile; the CTU mirror is now the official fallback
Verdict
Worth a look if you’re building classical-to-learned matching pipelines or need a well-benchmarked baseline for patch descriptors. Skip if you want an end-to-end image retrieval system; this is the descriptor layer only, and the good retrieval numbers require external bag-of-words machinery.
Frequently asked
- What is DagnyT/hardnet?
- HardNet trains image patch descriptors by deliberately mining the hardest negatives, not the closest misses.
- Is hardnet open source?
- Yes — DagnyT/hardnet is open source, released under the MIT license.
- What language is hardnet written in?
- DagnyT/hardnet is primarily written in Python.
- How popular is hardnet?
- DagnyT/hardnet has 533 stars on GitHub.
- Where can I find hardnet?
- DagnyT/hardnet is on GitHub at https://github.com/DagnyT/hardnet.