ChenglongChen/pytorch-DRL
A PyTorch zoo for RL algorithms that mostly stays in the CartPole gym
Modular implementations of A2C through PPO, with multi-agent ambitions but single-agent receipts so far.
Not currently ranked — collecting fresh signals.
star history
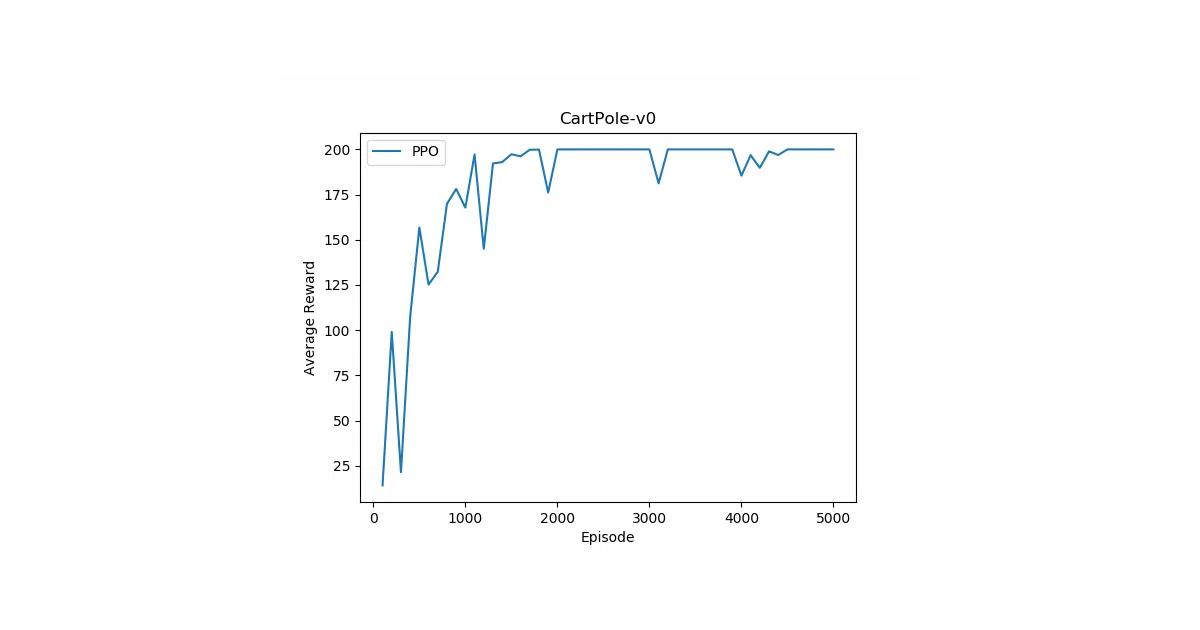
What it does This repo collects PyTorch rewrites of standard deep reinforcement learning algorithms—A2C, ACKTR, DQN, DDPG, PPO—behind a shared agent interface. Each algorithm gets the same six methods (interact, train, explore, act, value, evaluate), so swapping one for another is mostly a constructor change. The author also flags multi-agent as a target, though the current code and results are strictly single-agent.
The interesting bit The modular design is the actual contribution here. Most RL repos are algorithm-specific forks; this one tries to factor out the common scaffolding—experience collection, n-step returns, action noise—so the algorithms share legs. Whether that abstraction holds up under harder environments than CartPole is left as an exercise.
Key highlights
- Unified agent API across all five algorithms
- Supports both 1-step and n-step experience collection
- Includes KFAC optimizer borrowed from Kostrikov’s reference implementation
- All demonstrated results are on classic control tasks (CartPole, Pendulum)
- MIT licensed, minimal dependencies (PyTorch, gym, Python 3.6)
Caveats
- Several checklist items in the README remain unchecked, including the multi-agent code and TRPO/LOLA additions
- The author openly warns that RL reproduction is fragile; your seeds and hyperparameters will diverge
- No benchmark comparisons against reference implementations or baselines
Verdict Useful if you’re teaching RL or need a clean, hackable PyTorch skeleton to compare algorithm variants side-by-side. Skip it if you want battle-tested, production-grade implementations or anything beyond toy environments.
Frequently asked
- What is ChenglongChen/pytorch-DRL?
- Modular implementations of A2C through PPO, with multi-agent ambitions but single-agent receipts so far.
- Is pytorch-DRL open source?
- Yes — ChenglongChen/pytorch-DRL is open source, released under the MIT license.
- What language is pytorch-DRL written in?
- ChenglongChen/pytorch-DRL is primarily written in Python.
- How popular is pytorch-DRL?
- ChenglongChen/pytorch-DRL has 617 stars on GitHub.
- Where can I find pytorch-DRL?
- ChenglongChen/pytorch-DRL is on GitHub at https://github.com/ChenglongChen/pytorch-DRL.