ChenglongChen/kaggle-CrowdFlower
How to win a Kaggle NLP comp: 35 models and a prayer to the median god
A 2015 search-relevance competition winner that shows how far you can get with stacked XGBoost and brute-force ensembling.
Not currently ranked — collecting fresh signals.
star history
What it does
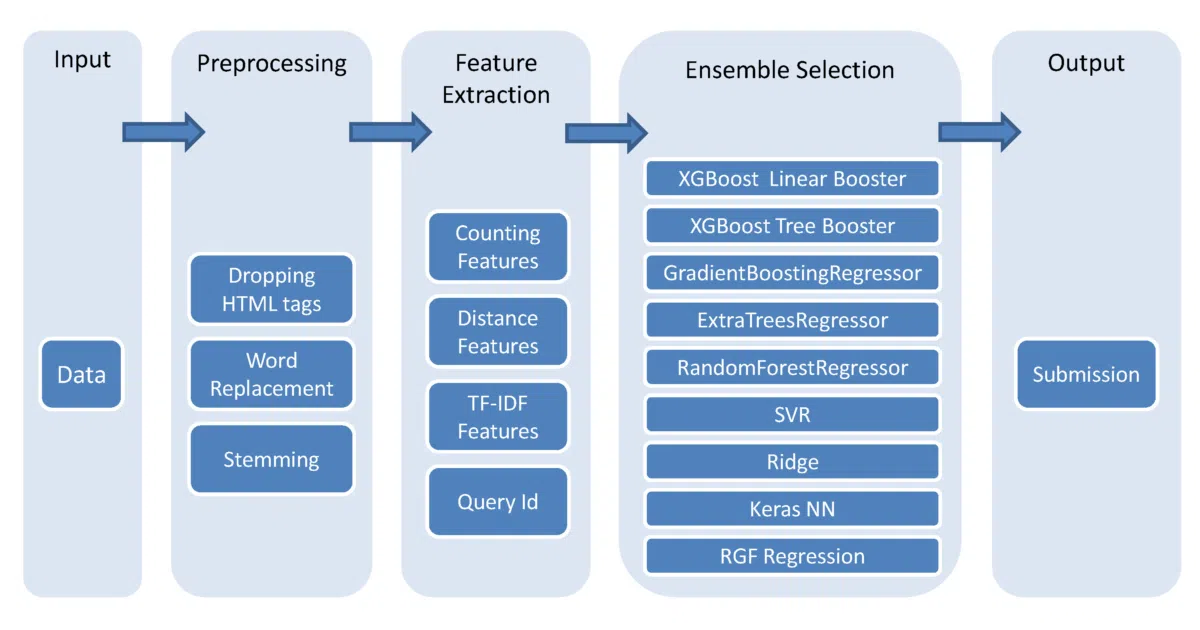
This is the first-place solution for a Kaggle competition where the goal was predicting how relevant a product search result is to a query. The pipeline generates features (SVD, bag-of-words, and more), trains a library of models, then ensembles the best 35 submissions by median. The best single model hit 0.70768 on the private leaderboard; the ensemble pushed that to 0.72189.
The interesting bit
The author openly admits the code is messy and points to a later repo (Home Depot) for a “clean and modularized” version. That honesty is refreshing, and the flowchart at least tries to make sense of the chaos. The real lesson is in the numbers: a 1.4-point jump from single model to median ensemble, which suggests the gains came more from variance reduction than from a single brilliant insight.
Key highlights
- XGBoost with linear booster as the workhorse single model
- Median ensemble of 35 public-LB-tuned submissions for the win
- Feature generation via
run_all.py— “a few hours” of compute - Full pipeline: feature extraction → model library → ensemble selection
- Pre-generated submission files if you just want the answer
Caveats
- The README warns the model-library step is “quite time consuming”
- Code is explicitly described as not clean or modular; expect archaeology
- Competition data is from 2015 and not included; you must source it yourself
Verdict
Worth studying if you’re learning how Kaggle ensembles actually get built in practice, or if you need a reference for text relevance scoring. Skip it if you want production-ready code — the author already told you where to look for that.
Frequently asked
- What is ChenglongChen/kaggle-CrowdFlower?
- A 2015 search-relevance competition winner that shows how far you can get with stacked XGBoost and brute-force ensembling.
- Is kaggle-CrowdFlower open source?
- Yes — ChenglongChen/kaggle-CrowdFlower is an open-source project tracked on heatdrop.
- What language is kaggle-CrowdFlower written in?
- ChenglongChen/kaggle-CrowdFlower is primarily written in C++.
- How popular is kaggle-CrowdFlower?
- ChenglongChen/kaggle-CrowdFlower has 1.8k stars on GitHub.
- Where can I find kaggle-CrowdFlower?
- ChenglongChen/kaggle-CrowdFlower is on GitHub at https://github.com/ChenglongChen/kaggle-CrowdFlower.