BruceMacD/chatd
Local RAG without the yak shaving
An Electron app that bundles its own LLM runner so you can chat with documents without touching a terminal.
Not currently ranked — collecting fresh signals.
star history
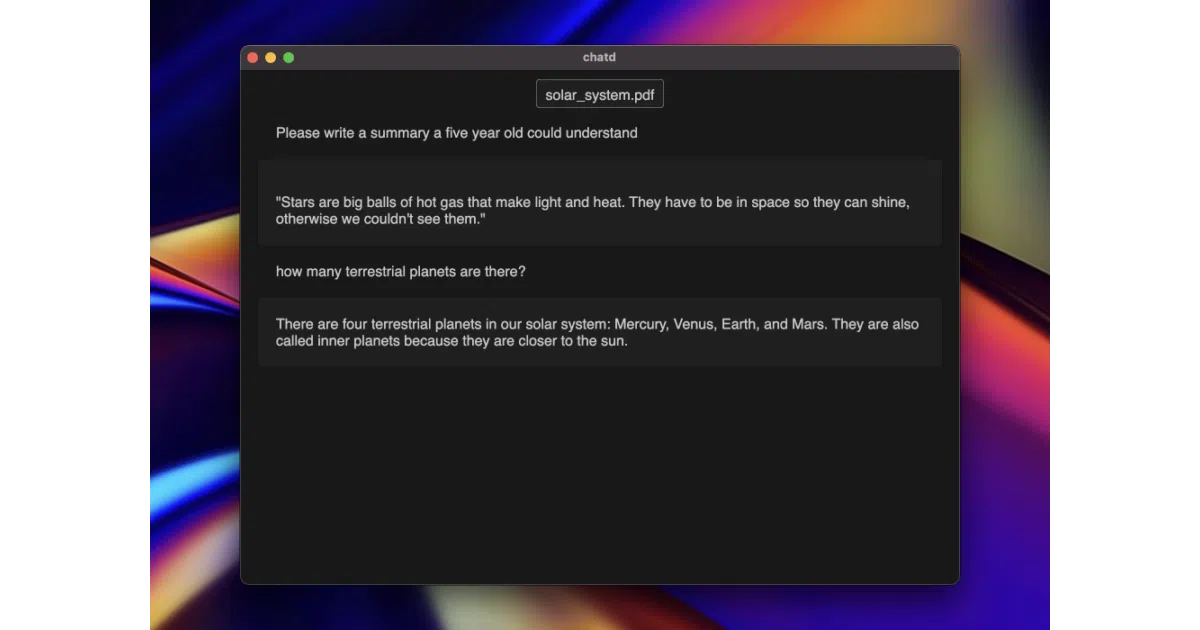
What it does
Chatd is an Electron desktop app for document Q&A using local AI. It ships with Ollama baked in, so you download, unzip, and run—no separate LLM installation, no cloud data, no terminal gymnastics. It defaults to Mistral-7B and will latch onto an existing Ollama instance if you already have one running.
The interesting bit
The packaging is the product. Most “local RAG” tools assume you’ve already wrestled with model weights and CUDA drivers. Chatd treats Ollama as an embedded dependency, managing its lifecycle automatically. That’s a genuine UX bet, not just a UI skin.
Key highlights
- Zero-dependency executable: Ollama runner bundled for macOS, Windows, and Linux
- Auto-detects existing local Ollama servers; starts its own if absent
- GPU support and custom model selection documented but off the happy path
- Unsigned Windows builds (you’ll get a security warning)
- macOS builds require Apple Developer signing for distribution beyond the build machine
Caveats
- The README doesn’t specify how document ingestion or chunking actually works—whether it’s simple full-text, vector search, or something else is unclear
- No mention of supported file formats (PDF? DOCX? TXT?)
- Windows and macOS packaging friction suggests this is still closer to “advanced user with patience” than “grandparent-friendly”
Verdict
Worth a look if you want local document chat without assembling the plumbing yourself. Skip it if you need fine-grained control over embedding models, chunking strategy, or already have a slick Ollama workflow you’re happy with.
Frequently asked
- What is BruceMacD/chatd?
- An Electron app that bundles its own LLM runner so you can chat with documents without touching a terminal.
- Is chatd open source?
- Yes — BruceMacD/chatd is open source, released under the MIT license.
- What language is chatd written in?
- BruceMacD/chatd is primarily written in JavaScript.
- How popular is chatd?
- BruceMacD/chatd has 1.1k stars on GitHub.
- Where can I find chatd?
- BruceMacD/chatd is on GitHub at https://github.com/BruceMacD/chatd.