Brokenwind/BertSimilarity
BERT sentence similarity, the 2019 way
A straightforward TensorFlow 1 implementation for comparing Chinese sentences with Google's BERT, before sentence-transformers made this trivial.
Not currently ranked — collecting fresh signals.
star history
What it does
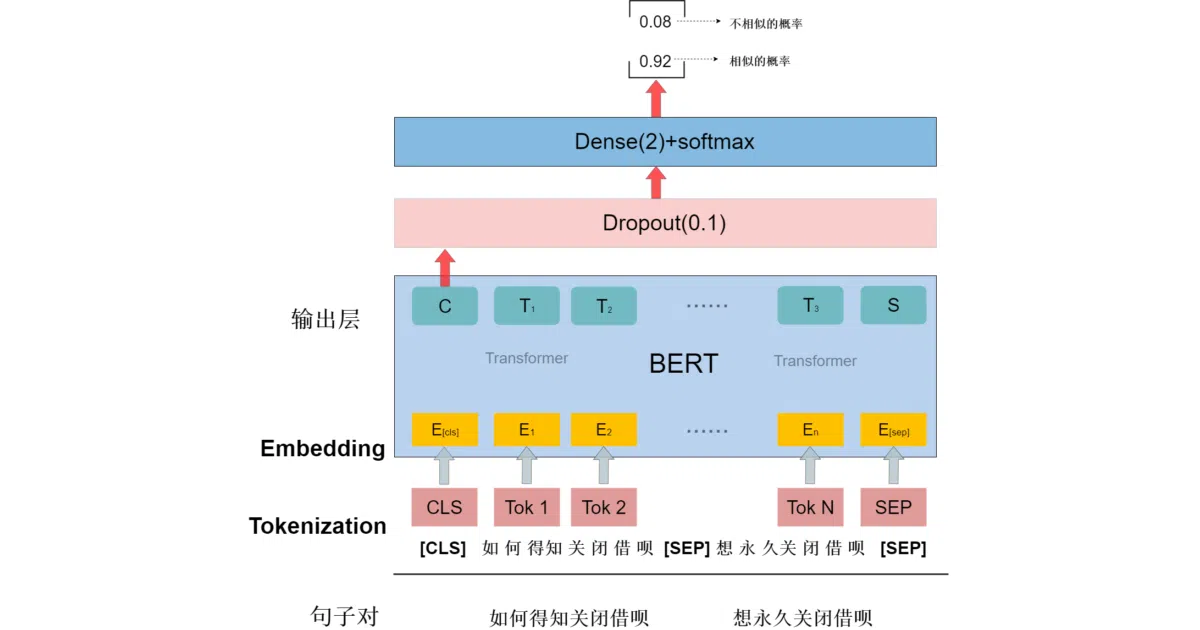
Takes two sentences, glues them together with [CLS] and [SEP] tokens, runs them through a 12-layer Chinese BERT model, then slaps a dropout layer and a 2-output fully-connected head on top. Out pops a softmax probability: similar or not. The repo includes shell scripts for training, evaluation, and an interactive inference mode where you type two sentences and get a verdict.
The interesting bit
This is essentially a time capsule of pre-fine-tuning BERT usage—circa 2018, when people still wrote their own classification heads and wrestled with TensorFlow 1. The author even hosts a pretrained model on Baidu Pan with extraction code fud8, which feels charmingly era-appropriate.
Key highlights
- Hardcoded for Chinese text with character-level tokenization (no word segmentation)
- Caps sentence pairs at length 30; longer pairs get truncated
- Ships with a convenience
start.shscript for train/eval/infer modes - Provides a pretrained checkpoint for those without GPU patience
- TensorFlow 1 dependency (the README is explicit about this)
Caveats
- Stuck on TensorFlow 1, which is now well past end-of-life
- No mention of performance metrics, dataset details, or how the pretrained model was trained
- The 30-token limit is quite restrictive for modern use
Verdict
Worth a look if you’re maintaining legacy Chinese NLP pipelines or need to understand how BERT similarity was done before sentence-transformers existed. Everyone else should probably just use sentence-transformers or a modern embedding API.
Frequently asked
- What is Brokenwind/BertSimilarity?
- A straightforward TensorFlow 1 implementation for comparing Chinese sentences with Google's BERT, before sentence-transformers made this trivial.
- Is BertSimilarity open source?
- Yes — Brokenwind/BertSimilarity is an open-source project tracked on heatdrop.
- What language is BertSimilarity written in?
- Brokenwind/BertSimilarity is primarily written in Python.
- How popular is BertSimilarity?
- Brokenwind/BertSimilarity has 510 stars on GitHub.
- Where can I find BertSimilarity?
- Brokenwind/BertSimilarity is on GitHub at https://github.com/Brokenwind/BertSimilarity.