AstarLight/CPS-OCR-Engine
When Tesseract fails and Baidu bills you, build your own
A Chinese-printed-character OCR engine born from frustration with existing tools and a university finance-office side project.
Not currently ranked — collecting fresh signals.
star history
What it does
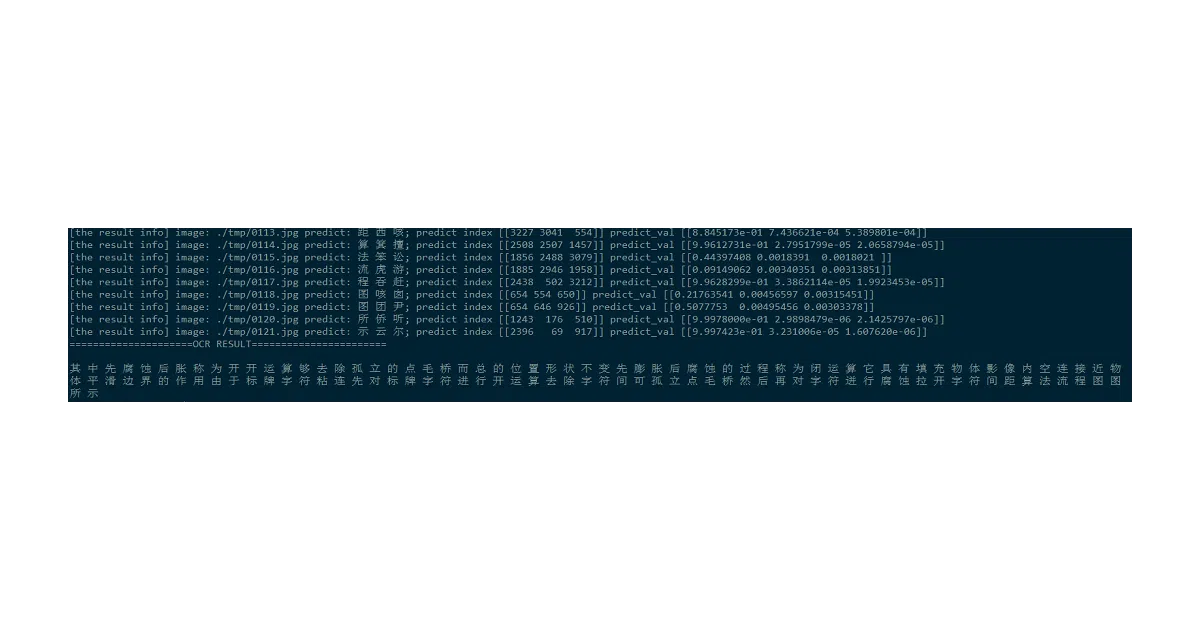
CPS-OCR-Engine recognizes 3,755 printed Chinese characters (Level 1 character set) from scanned documents, IDs, and invoices. It trains on synthetically generated data and runs inference by dropping images into a tmp directory. The author built it to power an intelligent bill-processing system for their university’s finance office.
The interesting bit
The synthetic data pipeline is the quiet workhorse: gen_printed_char.py renders training samples from Chinese font files with configurable rotation, margins, and sizes. No manual labeling required. The author claims top-1 accuracy of 0.99826 and top-5 of 0.99989, though the benchmark source and test conditions are unspecified.
Key highlights
- Synthetic training data generation from fonts with rotation up to 30 degrees
- Single-script workflow: train, validate, and infer through
Chinese_OCR.pymodes - Pre-trained model distributed via Baidu Pan (link + password in README)
- Focused scope: printed Chinese only, not handwritten or multi-language
- Accompanying blog post with implementation details (Chinese language)
Caveats
- README is entirely in Chinese; code comments and CLI help may be too
- Pre-trained model hosted on Baidu Pan, which requires an account and is region-restricted
- No mention of framework version, dependencies, or installation steps
- Character recognition requires pre-segmented single-character images; no line or paragraph detection shown
Verdict Worth a look if you need printed Chinese OCR and can read Chinese documentation or don’t mind spelunking. Skip if you need multilingual support, handwriting recognition, or a batteries-included pipeline with text detection and layout analysis.
Frequently asked
- What is AstarLight/CPS-OCR-Engine?
- A Chinese-printed-character OCR engine born from frustration with existing tools and a university finance-office side project.
- Is CPS-OCR-Engine open source?
- Yes — AstarLight/CPS-OCR-Engine is an open-source project tracked on heatdrop.
- What language is CPS-OCR-Engine written in?
- AstarLight/CPS-OCR-Engine is primarily written in Python.
- How popular is CPS-OCR-Engine?
- AstarLight/CPS-OCR-Engine has 1.1k stars on GitHub.
- Where can I find CPS-OCR-Engine?
- AstarLight/CPS-OCR-Engine is on GitHub at https://github.com/AstarLight/CPS-OCR-Engine.