Alibaba-NLP/DeepResearch
Alibaba open-sources a 30B-parameter agent for deep web research
An open-source 30B MoE agent trained to autonomously dig through the web for answers that require more than a single search.
Velocity · 7d
+6.4
★ / day
Trend
→steady
star history
What it does Tongyi DeepResearch is a 30.5-billion-parameter mixture-of-experts model—only 3.3 billion parameters activate per token—developed by Alibaba’s Tongyi Lab. It is designed specifically for long-horizon, deep information-seeking tasks, essentially acting as an autonomous research agent that can search, browse, and synthesize information across the web. The model supports two inference modes: a standard ReAct loop for core capability evaluation and a heavier IterResearch mode that applies test-time scaling to push performance higher.
The interesting bit Instead of just fine-tuning on static corpora, the team built a fully automated synthetic data pipeline for agentic pre-training, then applied end-to-end reinforcement learning using a customized Group Relative Policy Optimization framework with token-level gradients and selective negative-sample filtering to keep training stable in a non-stationary environment. That is a lot of machinery to teach a model how to keep clicking “next page” without losing its mind.
Key highlights
- 30.5B total parameters with 3.3B active per token and a 128K context window.
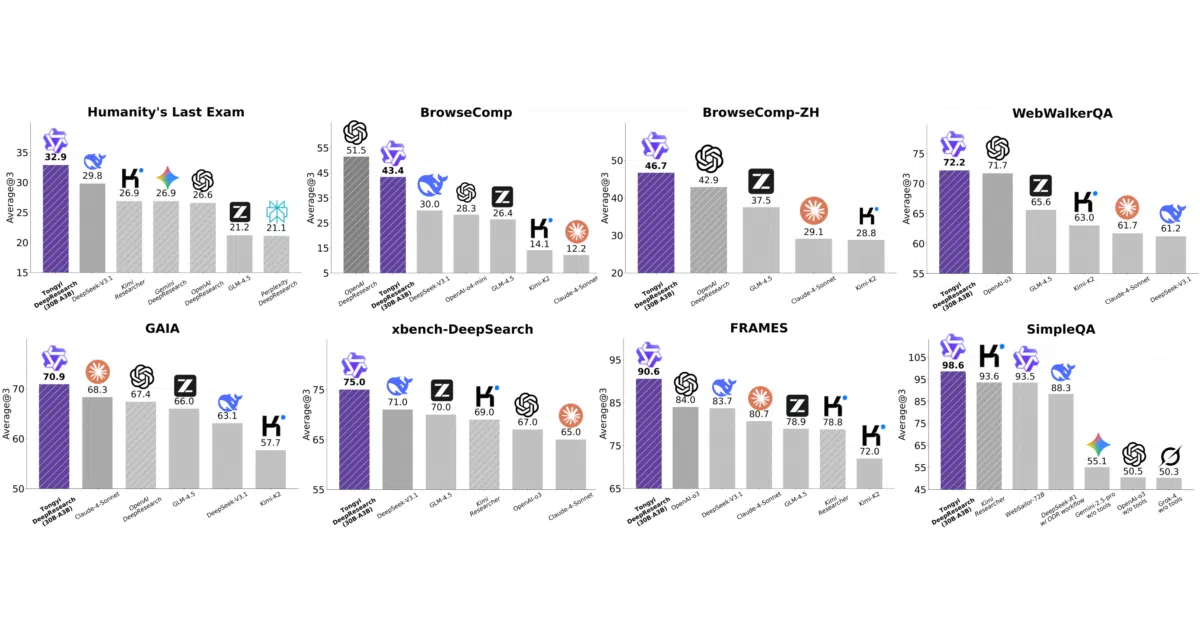
- Claims state-of-the-art results on agentic search benchmarks including Humanity’s Last Exam, BrowseComp, and FRAMES.
- Two inference paradigms: ReAct for intrinsic ability evaluation and an IterResearch-based “Heavy” mode for scaled test-time reasoning.
- Released model weights on HuggingFace and ModelScope, plus an OpenRouter API endpoint for GPU-free usage.
- Underlying training relies on a fully automated synthetic data generation pipeline covering pre-training, SFT, and RL stages.
Caveats
- Running inference locally requires a constellation of external API keys—search, webpage reading, summarization, file parsing, and a Python sandbox—so it is not a fully offline, self-contained agent out of the box.
- The online demos are explicitly labeled as “quick exploration only” and may fail intermittently due to model latency and tool rate limits; the README steers production use toward Alibaba’s Bailian cloud service.
- The README recommends Python 3.10.0 specifically and warns that other versions may cause dependency issues.
Verdict Worth a look if you are building autonomous research agents or studying RL-driven tool use at scale; skip it if you need a plug-and-play local assistant that does not depend on half a dozen external SaaS APIs.
Frequently asked
- What is Alibaba-NLP/DeepResearch?
- An open-source 30B MoE agent trained to autonomously dig through the web for answers that require more than a single search.
- Is DeepResearch open source?
- Yes — Alibaba-NLP/DeepResearch is open source, released under the Apache-2.0 license.
- What language is DeepResearch written in?
- Alibaba-NLP/DeepResearch is primarily written in Python.
- How popular is DeepResearch?
- Alibaba-NLP/DeepResearch has 19.7k stars on GitHub and is currently holding steady.
- Where can I find DeepResearch?
- Alibaba-NLP/DeepResearch is on GitHub at https://github.com/Alibaba-NLP/DeepResearch.