Alexander-H-Liu/End-to-end-ASR-Pytorch
A PyTorch ASR toolkit that admits its own rough edges
A research-oriented end-to-end speech recognition implementation covering attention, CTC, and hybrid models—config-driven, but not production-polished.
Not currently ranked — collecting fresh signals.
star history
What it does
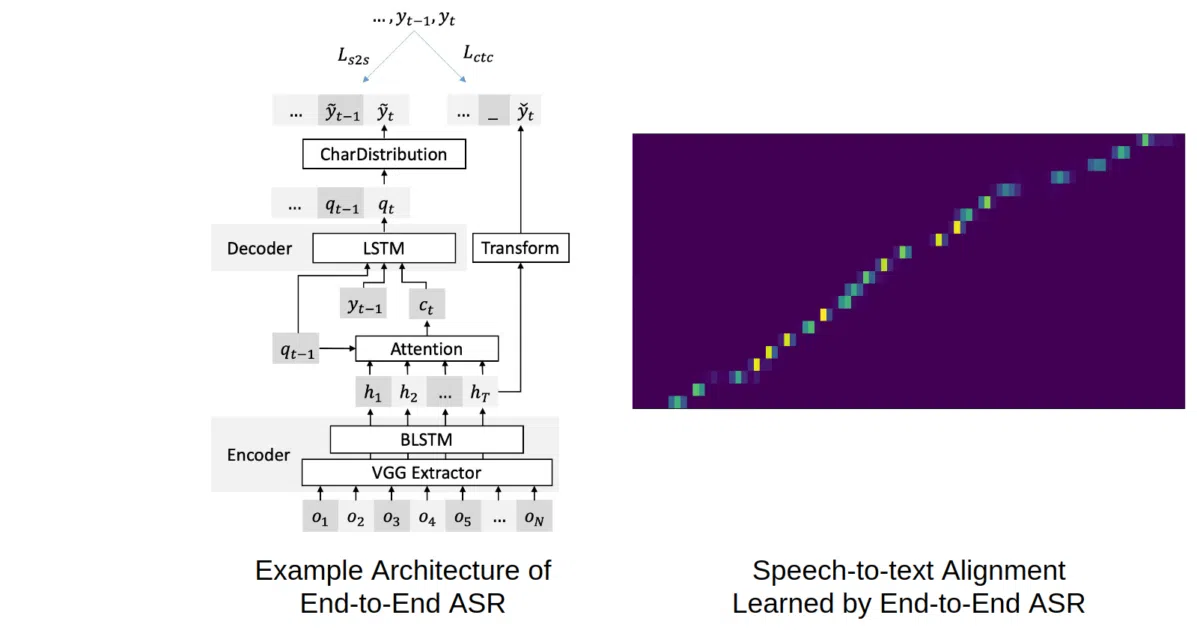
This is a PyTorch implementation of Listen, Attend and Spell (LAS) and friends: seq2seq attention-based ASR, pure CTC, and joint CTC-attention hybrids. It handles the full pipeline from on-the-fly feature extraction through training to beam-search decoding with optional RNN language model fusion. Everything is driven by YAML config files, with TensorBoard logging baked in.
The interesting bit
The authors don’t pretend this is a turnkey product. The README explicitly warns that example configs “were not fine-tuned,” that TensorBoard error rates are biased (see issue #10), and that CuDNN CTC is “unstable.” That honesty is refreshing in a field of overclaimed benchmarks. The project also serves as a reference implementation for multiple papers, with citations requested rather than demanded.
Key highlights
- On-the-fly feature extraction via torchaudio; character, subword (sentencepiece), or word encoding
- Seq2seq, CTC, and joint CTC-attention training with yaml-driven hyperparameters
- Beam search, greedy decoding, and joint decoding with external RNN-LM
- TensorBoard visualization including attention alignment plots
- Direct lineage from ESPnet and consultation with William Chan (first LAS author)
Caveats
- Decoding is single-sample (no batching), so RAM usage scales with worker count
- Several items remain on the TODO list: pure CTC training has a beam decode bug, examples are “coming soon,” and CLM migration is unfinished
- The project appears to be in maintenance mode; last significant activity unclear from README alone
Verdict
Worth a look for researchers or students who want to understand LAS/CTC internals and don’t mind tuning configs themselves. Skip it if you need a battle-tested, production-ready ASR pipeline—this is a teaching and experimentation scaffold, not a shipped product.
Frequently asked
- What is Alexander-H-Liu/End-to-end-ASR-Pytorch?
- A research-oriented end-to-end speech recognition implementation covering attention, CTC, and hybrid models—config-driven, but not production-polished.
- Is End-to-end-ASR-Pytorch open source?
- Yes — Alexander-H-Liu/End-to-end-ASR-Pytorch is open source, released under the MIT license.
- What language is End-to-end-ASR-Pytorch written in?
- Alexander-H-Liu/End-to-end-ASR-Pytorch is primarily written in Python.
- How popular is End-to-end-ASR-Pytorch?
- Alexander-H-Liu/End-to-end-ASR-Pytorch has 1.2k stars on GitHub.
- Where can I find End-to-end-ASR-Pytorch?
- Alexander-H-Liu/End-to-end-ASR-Pytorch is on GitHub at https://github.com/Alexander-H-Liu/End-to-end-ASR-Pytorch.