zilliztech/GPTCache
Pay once, answer twice: semantic caching for LLMs
It cuts LLM API costs and latency by remembering answers to questions that are similar, not just identical.
Not currently ranked — collecting fresh signals.
star history
What it does
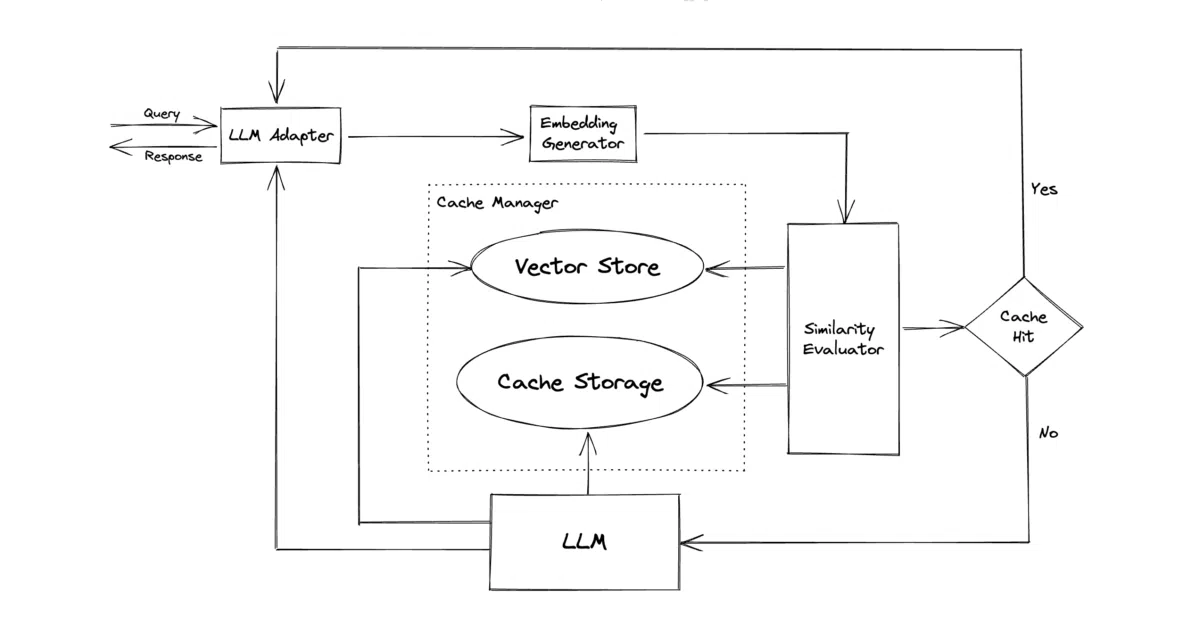
GPTCache intercepts calls to LLM APIs and stores the resulting prompts and responses. When a new request arrives, it checks whether the question has been asked before—either verbatim or in a semantically similar form—and returns the cached answer if so. It integrates with LangChain, LlamaIndex, and OpenAI, and also runs as a standalone Docker server for stacks that don’t speak Python.
The interesting bit
Instead of simple string matching, the cache embeds queries and searches a vector store to decide whether a previous answer is “close enough.” A configurable temperature parameter lets you tune how aggressively it skips the cache, which is a rare admission that sometimes you actually want to pay for a fresh answer.
Key highlights
- Project claims up to 10× cost savings and 100× latency improvement by avoiding redundant API calls.
- Supports exact-match and semantic retrieval via vector backends such as FAISS paired with SQLite.
- Provides adapters for LangChain, LlamaIndex, Replicate, and OpenAI, plus a language-agnostic server mode.
- Includes a
temperatureknob to probabilistically bypass the cache when fresher output is desired. - Boots with a minimal dependency set and auto-installs extra libraries only when advanced features are used.
Caveats
- The README warns that the project is under heavy development and the API may change at any time.
- Maintainers have stopped adding native adapters for new LLM APIs or models, steering users toward generic
get/setAPIs instead.
Verdict
Useful if your workload repeats or paraphrases the same questions and you need to shave token spend. Less compelling if every query is unique or you require answers from the latest model endpoints not yet supported.
Frequently asked
- What is zilliztech/GPTCache?
- It cuts LLM API costs and latency by remembering answers to questions that are similar, not just identical.
- Is GPTCache open source?
- Yes — zilliztech/GPTCache is open source, released under the MIT license.
- What language is GPTCache written in?
- zilliztech/GPTCache is primarily written in Python.
- How popular is GPTCache?
- zilliztech/GPTCache has 8.1k stars on GitHub.
- Where can I find GPTCache?
- zilliztech/GPTCache is on GitHub at https://github.com/zilliztech/GPTCache.