zai-org/VisualGLM-6B
ChatGLM grows eyes: a bilingual vision model for modest GPUs
It bolts a BLIP2-Qformer vision encoder onto ChatGLM-6B to answer bilingual questions about images on consumer hardware.
Not currently ranked — collecting fresh signals.
star history
What it does
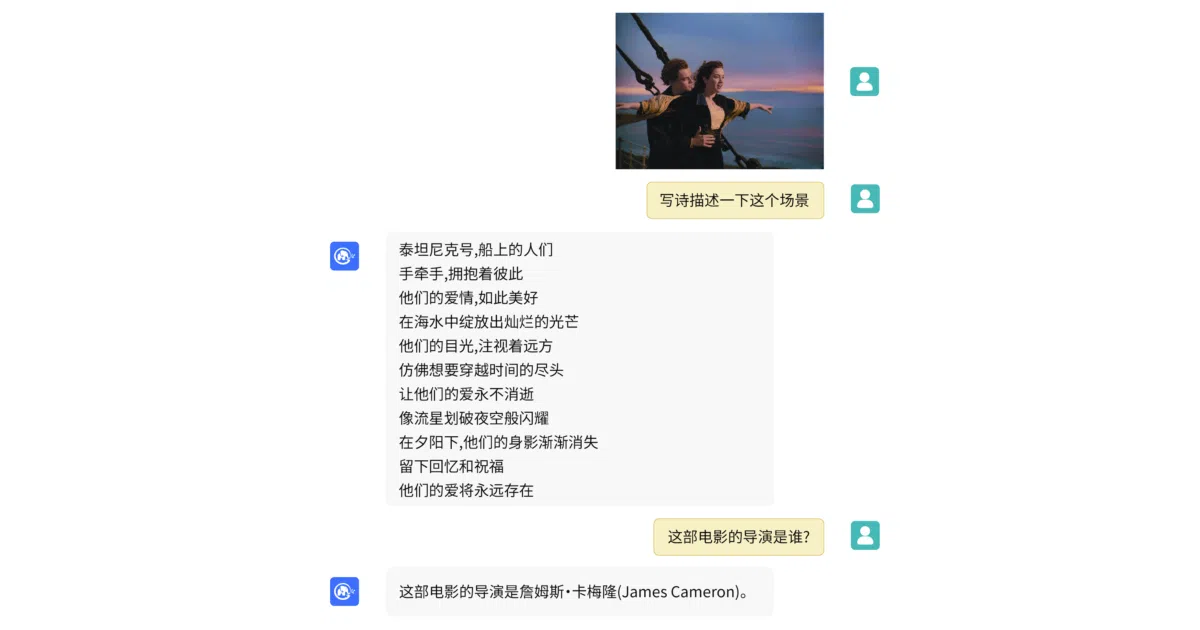
VisualGLM-6B is a 7.8-billion-parameter multimodal chat model that accepts images and converses in Chinese or English. It bolts a BLIP2-Qformer vision encoder onto the ChatGLM-6B backbone, aligning visual features into the language model’s semantic space using 30 million Chinese and 300 million English image-text pairs. After pre-training, it is fine-tuned on long-form visual question-answering data to produce conversational responses about whatever is in the photo.
The interesting bit
The project is deliberately designed for modest hardware: with INT4 quantization it claims to run on consumer GPUs with as little as 6.3 GB of VRAM. The maintainers also ship both a HuggingFace Transformers interface and a lower-level SwissArmyTransformer backend, so you can pick between convenience and surgical fine-tuning via LoRA or QLoRA.
Key highlights
- Bilingual by design: trained with equal weighting on Chinese and English image-text pairs, rather than retrofitting a mostly-English model.
- Two APIs for two audiences: HuggingFace Transformers for quick prototyping, SwissArmyTransformer for researchers who want to tweak internals.
- Fine-tuning demos show real improvement: the provided 20-image “background” task example moves the model from hallucinating generic advice to describing actual floors and keyboards.
- Ecosystem sprawl: community forks like XrayGLM (medical imaging) and StarGLM (astronomy) suggest the base model is adaptable.
- Quantization-friendly: INT4 mode targets single-GPU deployment.
Caveats
- The authors explicitly label it v1 and warn of “considerable” limitations: factual hallucinations, missed image details, and susceptibility to being misled.
- The team already points users to their successor CogVLM (17B parameters, new visual-expert architecture), which suggests this model is no longer the flagship.
Verdict
Worth a look if you need a lightweight, bilingual vision-language model for research or domain-specific fine-tuning, but skip it if you want production-grade accuracy out of the box—the maintainers themselves recommend CogVLM for that.
Frequently asked
- What is zai-org/VisualGLM-6B?
- It bolts a BLIP2-Qformer vision encoder onto ChatGLM-6B to answer bilingual questions about images on consumer hardware.
- Is VisualGLM-6B open source?
- Yes — zai-org/VisualGLM-6B is open source, released under the Apache-2.0 license.
- What language is VisualGLM-6B written in?
- zai-org/VisualGLM-6B is primarily written in Python.
- How popular is VisualGLM-6B?
- zai-org/VisualGLM-6B has 4.2k stars on GitHub.
- Where can I find VisualGLM-6B?
- zai-org/VisualGLM-6B is on GitHub at https://github.com/zai-org/VisualGLM-6B.