zai-org/ChatGLM2-6B
A 6B-parameter LLM that runs on a GTX 1060
ChatGLM2-6B squeezes bilingual chat into consumer GPUs through aggressive quantization and attention tricks.
Not currently ranked — collecting fresh signals.
star history
What it does ChatGLM2-6B is a 6-billion-parameter Chinese-English dialogue model from Tsinghua’s THUDM lab. It packs INT4 quantization tight enough to run on 6GB VRAM, supports 8K context in chat (32K in a separate variant), and ships with P-Tuning v2 and full fine-tuning scripts. The repo is essentially a HuggingFace wrapper plus inference examples and evaluation benchmarks.
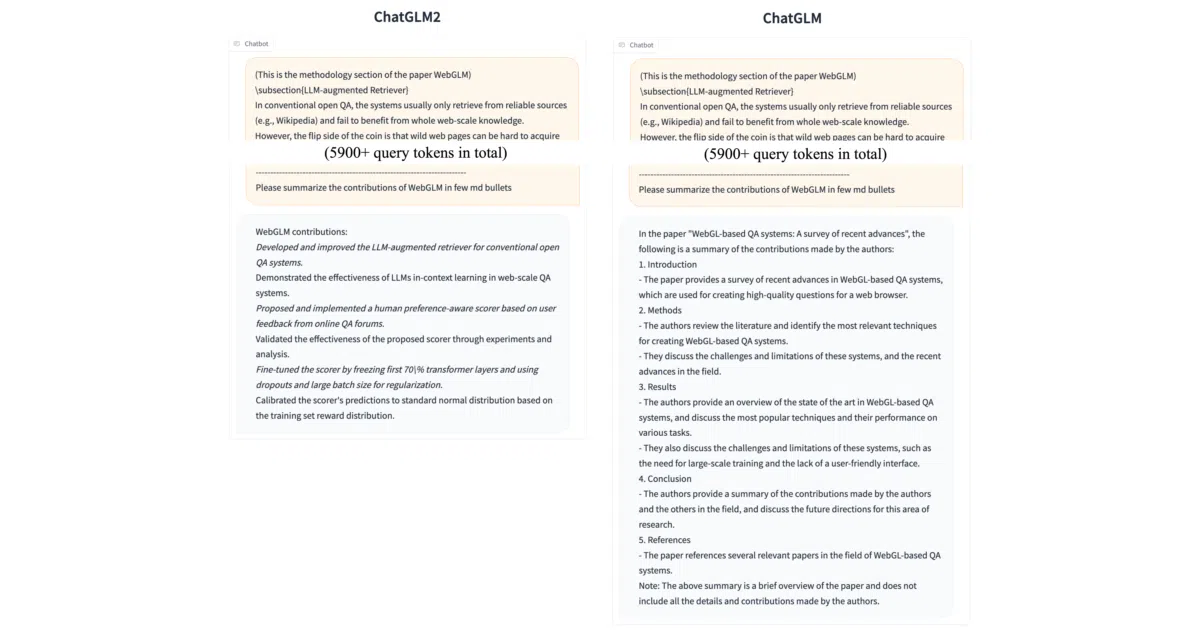
The interesting bit The real engineering is in the memory math, not the parameter count. Multi-Query Attention slashes KV cache size, and the model reuses previous turns’ caches via Causal Mask training—so a conversation that would asphyxiate the first-gen ChatGLM-6B after 1,119 characters keeps breathing past 8,192 on the same 6GB card. That’s a 7× context win without buying new hardware.
Key highlights
- INT4 inference needs only 5.1–5.5 GB VRAM; INT8 sits at ~8 GB
- Benchmark jumps are lopsided: +571% on GSM8K math versus ChatGLM-6B, though MMLU gains a more modest +23%
- FlashAttention-backed context stretching to 32K in the dedicated -32K variant
- Free commercial use after a registration questionnaire; fully open for research
- PyTorch 2.0+ strongly recommended—older versions fall back to naive attention and balloon memory
Caveats
- The README is upfront that 6B parameters means hallucination and misleading outputs are guaranteed risks, not edge cases
- The team explicitly disclaims any downstream apps; you’re on your own for safety review and deployment
- Quantization costs a few points on MMLU and C-Eval, though the README calls it “acceptable”
Verdict Worth a look if you need bilingual Chinese-English chat on constrained hardware or want a permissively licensed base to fine-tune. Skip it if you need state-of-the-art reasoning out of the box—those GSM8K gains start from a very low baseline.
Frequently asked
- What is zai-org/ChatGLM2-6B?
- ChatGLM2-6B squeezes bilingual chat into consumer GPUs through aggressive quantization and attention tricks.
- Is ChatGLM2-6B open source?
- Yes — zai-org/ChatGLM2-6B is an open-source project tracked on heatdrop.
- What language is ChatGLM2-6B written in?
- zai-org/ChatGLM2-6B is primarily written in Python.
- How popular is ChatGLM2-6B?
- zai-org/ChatGLM2-6B has 15.5k stars on GitHub.
- Where can I find ChatGLM2-6B?
- zai-org/ChatGLM2-6B is on GitHub at https://github.com/zai-org/ChatGLM2-6B.