your-papa/obsidian-Smart2Brain
Chat with your Obsidian vault without sending notes to OpenAI
An Obsidian plugin that runs RAG locally via Ollama, or falls back to ChatGPT if you don't mind the cloud.
Not currently ranked — collecting fresh signals.
star history
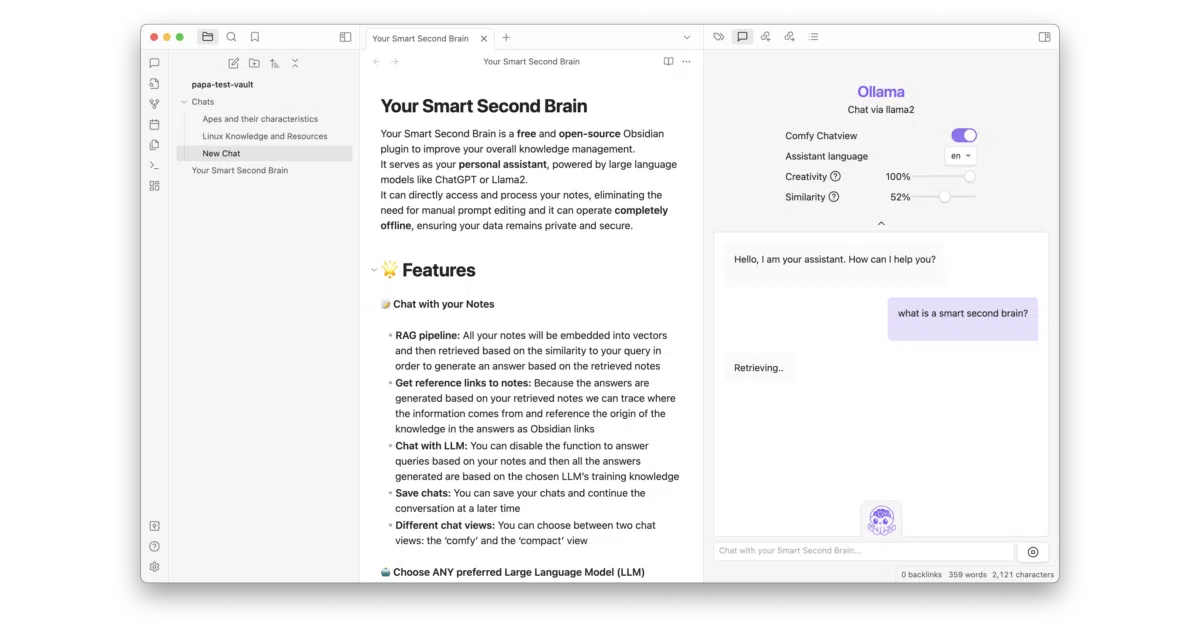
What it does
Smart2Brain embeds your Obsidian notes into a local vector store and retrieves relevant chunks when you ask questions, surfacing answers with clickable links back to source notes. It can run entirely offline through Ollama, or pipe queries to OpenAI’s models if you prefer capability over privacy. You can also disable RAG entirely and use it as a generic chat interface.
The interesting bit
The project started as a university assignment and now serves as an experimental playground for its authors. The RAG pipeline uses hierarchical tree summarization rather than simple chunking, and the whole stack—LangChain for orchestration, Orama for vector search—is open source, unlike some competing Obsidian AI plugins that require licenses for local model support.
Key highlights
- Local-first: Ollama integration keeps embeddings and inference on your machine
- Cited answers: responses include Obsidian links to the originating notes
- Model switching: swap between LLMs for different tasks (e.g., scientific vs. persuasive writing)
- Two chat UIs: “comfy” and “compact” views
- Persistent chat histories you can resume later
Caveats
- Output quality hinges heavily on how well-structured your vault is; messy notes yield messy answers
- The authors note that “development setup instructions” are still TBD, so contributing may require some spelunking
- Obsidian Sync users must manually exclude the
vectorstoresfolder to avoid bloated version history
Verdict
Worth a look if you want private, cited Q&A over your own notes and don’t mind tuning your vault organization. Skip it if you need polished multi-language support or a mature plugin ecosystem—this is still a spare-time project with an ambitious roadmap.
Frequently asked
- What is your-papa/obsidian-Smart2Brain?
- An Obsidian plugin that runs RAG locally via Ollama, or falls back to ChatGPT if you don't mind the cloud.
- Is obsidian-Smart2Brain open source?
- Yes — your-papa/obsidian-Smart2Brain is open source, released under the MIT license.
- What language is obsidian-Smart2Brain written in?
- your-papa/obsidian-Smart2Brain is primarily written in TypeScript.
- How popular is obsidian-Smart2Brain?
- your-papa/obsidian-Smart2Brain has 1.2k stars on GitHub.
- Where can I find obsidian-Smart2Brain?
- your-papa/obsidian-Smart2Brain is on GitHub at https://github.com/your-papa/obsidian-Smart2Brain.