xingyizhou/ExtremeNet
Object detection without the region-classification treadmill
A 2019 CVPR paper that detects objects by finding five keypoints—four extremes and a center—then groups them geometrically into boxes.
Not currently ranked — collecting fresh signals.
star history
What it does
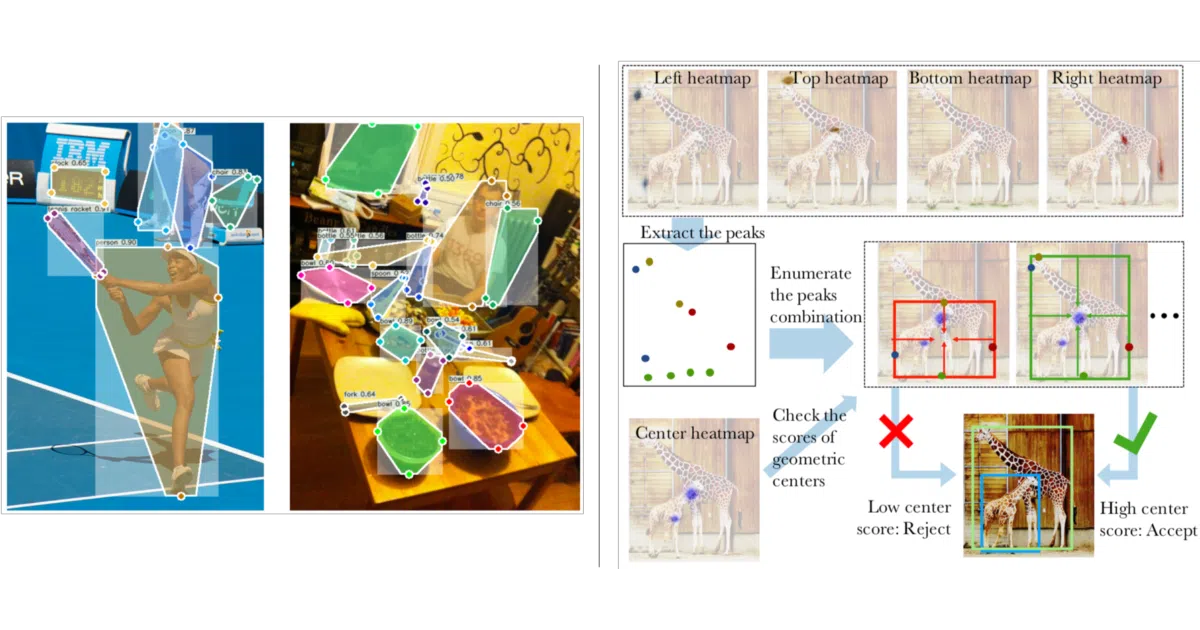
ExtremeNet treats object detection as pure keypoint estimation. A standard network predicts heatmaps for the top-most, left-most, bottom-most, right-most, and center points of each object. If five points align geometrically, they form a bounding box. No region proposals, no per-box classification, no implicit feature learning. The project includes training and evaluation code, plus optional integration with Deep Extreme Cut for instance segmentation.
The interesting bit
The extreme points themselves are useful: connecting them yields a coarse octagonal mask that scores 18.9% Mask AP on COCO, far above what a plain bounding box mask would achieve. Feed those extremes into DEXTR and you hit 34.6% Mask AP—competitive segmentation from detection side-effects.
Key highlights
- 43.2% box AP on COCO test-dev, 43.3% val AP with multi-scale testing
- Built on CornerNet’s codebase; fine-tunes from its 10-GPU pretrained model
- Optional
--show_maskdemo flag pipes results into DEXTR for full instance segmentation - Training demands 5× 12GB GPUs and ~10 days on Titan V hardware
- Includes tooling to generate extreme-point annotations from standard COCO segmentation masks
Caveats
- PyTorch 0.4.1 and Anaconda Python 3.6 only; this is 2019-era software
- Training from scratch lags 2 AP behind fine-tuning from CornerNet at the same iteration count
- The authors note evaluation with DEXTR masking is slow
Verdict
Worth studying if you’re researching keypoint-based detection or want to see how far bottom-up methods can stretch without region-based pipelines. Skip it if you need a modern, maintained detector—this is a research artifact, not a product.
Frequently asked
- What is xingyizhou/ExtremeNet?
- A 2019 CVPR paper that detects objects by finding five keypoints—four extremes and a center—then groups them geometrically into boxes.
- Is ExtremeNet open source?
- Yes — xingyizhou/ExtremeNet is open source, released under the BSD-3-Clause license.
- What language is ExtremeNet written in?
- xingyizhou/ExtremeNet is primarily written in Python.
- How popular is ExtremeNet?
- xingyizhou/ExtremeNet has 1k stars on GitHub.
- Where can I find ExtremeNet?
- xingyizhou/ExtremeNet is on GitHub at https://github.com/xingyizhou/ExtremeNet.