x4nth055/emotion-recognition-using-speech
A kitchen-sink approach to feeling out speech
This repo wraps sklearn classifiers and Keras RNNs into a single toolkit for detecting emotions from audio, complete with four baked-in datasets and a microphone test script.
Not currently ranked — collecting fresh signals.
star history
What it does
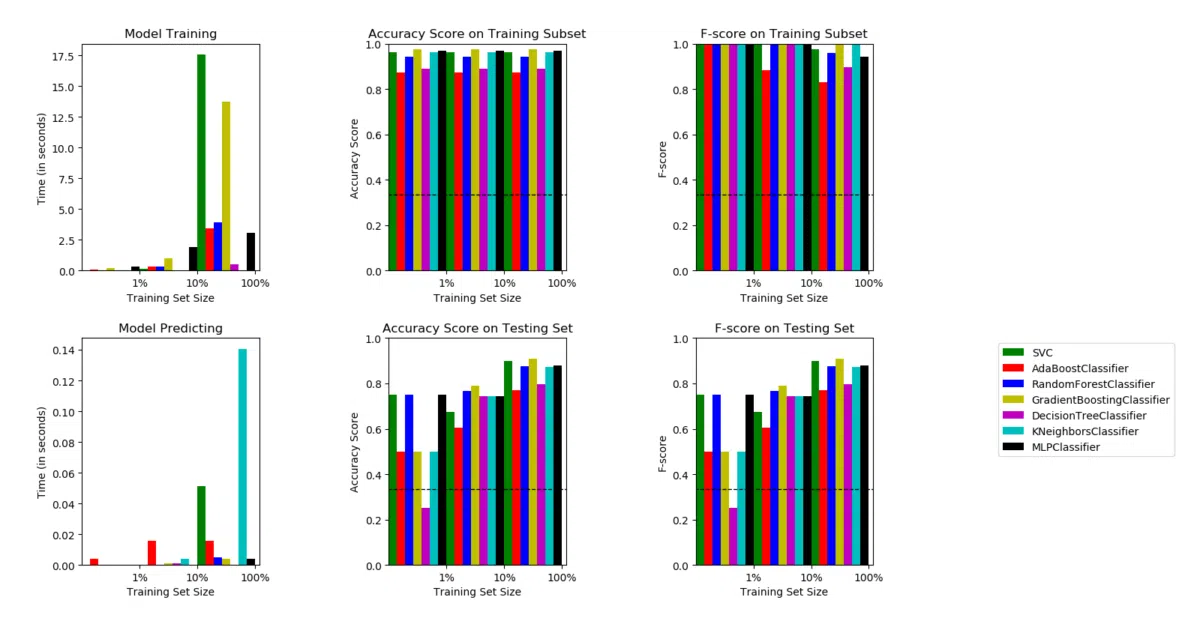
The project trains machine learning models to classify emotions from speech audio. It bundles four datasets (RAVDESS, TESS, EMO-DB, plus a custom noisy set), extracts standard audio features via librosa (MFCC, chromagram, mel spectrogram, contrast, tonnetz), and wraps both sklearn classifiers and Keras RNNs behind a unified Python interface. A test.py script lets you speak into a microphone for live prediction.
The interesting bit
The author did the tedious data-wrangling so you don’t have to: datasets are pre-formatted, features are pre-extracted on first run, and grid-search results are pickled for reuse. The “glue code” here is the value — it lowers the barrier from “I want to try speech emotion recognition” to actually running rec.train() in a few lines.
Key highlights
- Supports 9 emotion labels across 4 datasets, with optional class balancing
- 8 sklearn classifiers + RNNs (LSTM/GRU via Keras), plus regressor variants for 3- and 5-emotion subsets
- Automatic audio conversion to 16000Hz mono via ffmpeg if your files don’t match
- Pre-computed grid search results in
grid/folder; histogram plotting for model comparison - Live microphone testing with
python test.py
Caveats
- The README shows train scores of 1.0 against test scores of ~0.81–0.89, suggesting overfitting is present and unaddressed
- The “custom” dataset is explicitly described as “unbalanced noisy” — quality unclear
- librosa and scikit-learn versions are pinned to releases from 2018–2021; compatibility with current Python/package versions is untested
Verdict
Good for students or researchers who need a working baseline fast and don’t mind dated dependencies. Skip it if you need production-grade robustness or modern deep-learning architectures; the RNN implementation is basic (128-unit LSTM stacks) and the evaluation metrics are thin.
Frequently asked
- What is x4nth055/emotion-recognition-using-speech?
- This repo wraps sklearn classifiers and Keras RNNs into a single toolkit for detecting emotions from audio, complete with four baked-in datasets and a microphone test script.
- Is emotion-recognition-using-speech open source?
- Yes — x4nth055/emotion-recognition-using-speech is open source, released under the MIT license.
- What language is emotion-recognition-using-speech written in?
- x4nth055/emotion-recognition-using-speech is primarily written in Python.
- How popular is emotion-recognition-using-speech?
- x4nth055/emotion-recognition-using-speech has 690 stars on GitHub.
- Where can I find emotion-recognition-using-speech?
- x4nth055/emotion-recognition-using-speech is on GitHub at https://github.com/x4nth055/emotion-recognition-using-speech.