vearch/vearch
JD's vector database, now open-source and Helm-ready
A distributed vector search engine built for production RAG pipelines, with hybrid search and raft-based replication.
Not currently ranked — collecting fresh signals.
star history
What it does
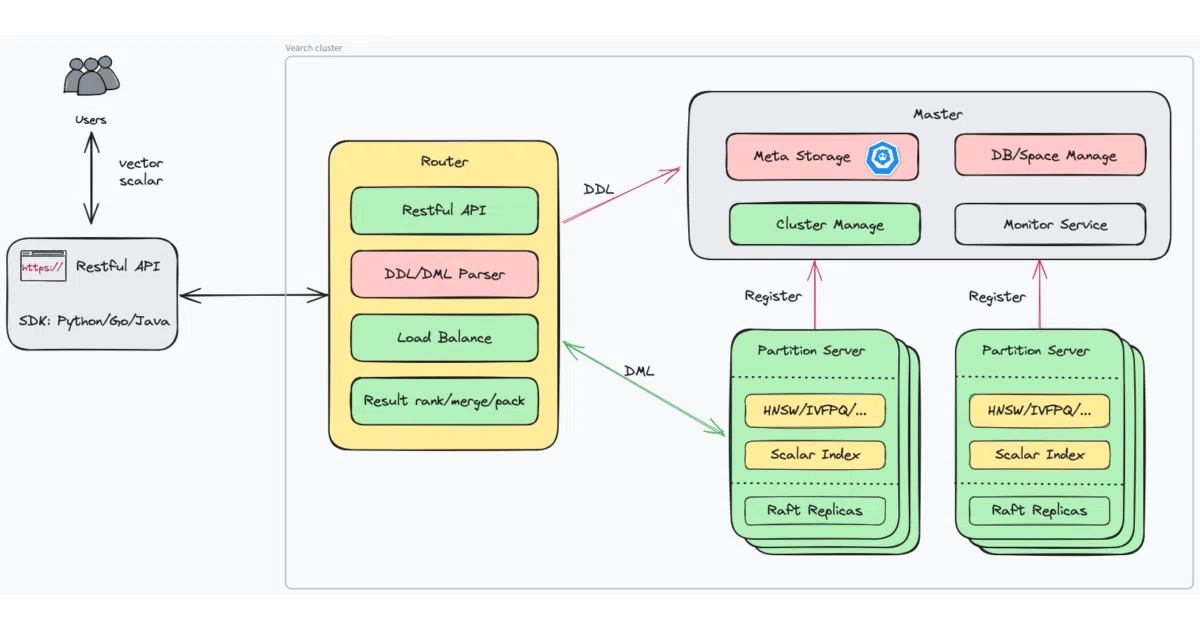
Vearch stores embedding vectors and runs similarity search at scale, backed by Faiss for the actual indexing. It adds scalar filtering, so you can combine vector similarity with metadata constraints like “only items in stock.” The system splits work across three roles: a Master for schema and coordination, Routers for REST API and request merging, and PartitionServers that replicate data via raft.
The interesting bit
The project originated at JD.com’s e-commerce platform — the academic citation is a 2019 paper on real-time visual search for billions of images. That retail-scale pedigree shows in the architecture: it’s designed as a complete distributed system rather than a single-node library with networking duct-taped on.
Key highlights
- Hybrid search: vector similarity plus scalar filtering in one query
- Deploy via Helm chart, Docker Compose (standalone or cluster), or source compile
- SDKs for Python, Go, Java, and Rust
- Ready-made integrations for LangChain, LlamaIndex, Langchaingo, and LangChain4j
- Core engine (Gamma) built on Faiss for vector indexing
Caveats
- The README claims “millions of objects in milliseconds” but offers no benchmarks, hardware specs, or comparison numbers to ground that
- The “billions of images” visual search demo requires an unspecified “image retrieval plugin” — not included in the repo
Verdict
Worth evaluating if you need a self-hosted vector database with hybrid search and explicit multi-node replication. Skip it if you’re already committed to a managed service or if your workload fits comfortably in a single-node solution like pgvector.
Frequently asked
- What is vearch/vearch?
- A distributed vector search engine built for production RAG pipelines, with hybrid search and raft-based replication.
- Is vearch open source?
- Yes — vearch/vearch is open source, released under the Apache-2.0 license.
- What language is vearch written in?
- vearch/vearch is primarily written in Go.
- How popular is vearch?
- vearch/vearch has 2.3k stars on GitHub.
- Where can I find vearch?
- vearch/vearch is on GitHub at https://github.com/vearch/vearch.