uxlfoundation/oneDAL
Intel's ML library that makes scikit-learn sweat
A C++/SYCL number-crunching engine that accelerates classic ML algorithms on CPUs, GPUs, and clusters—often without changing your Python code.
Not currently ranked — collecting fresh signals.
star history
What it does
oneDAL is Intel’s implementation of the oneAPI Data Analytics Library spec: a C++ and DPC++ library that accelerates bread-and-butter machine learning on tabular data—linear regression, K-means, random forests, and friends. It targets CPUs via SIMD and cache-aware code, GPUs via SYCL and oneMKL, and multi-node setups via MPI. Most Python users encounter it indirectly through scikit-learn-intelex, which swaps scikit-learn’s backends for oneDAL’s without rewriting code.
The interesting bit
The library’s real audience is split in two: Python data scientists who want free speedups on existing code, and C++ developers who need deterministic, hardware-exploiting ML kernels they can ship without a Python runtime. The SYCL angle matters here—this isn’t CUDA-locked; it’s Intel betting on cross-vendor GPU code that happens to run best on their silicon.
Key highlights
- Scikit-learn compatibility:
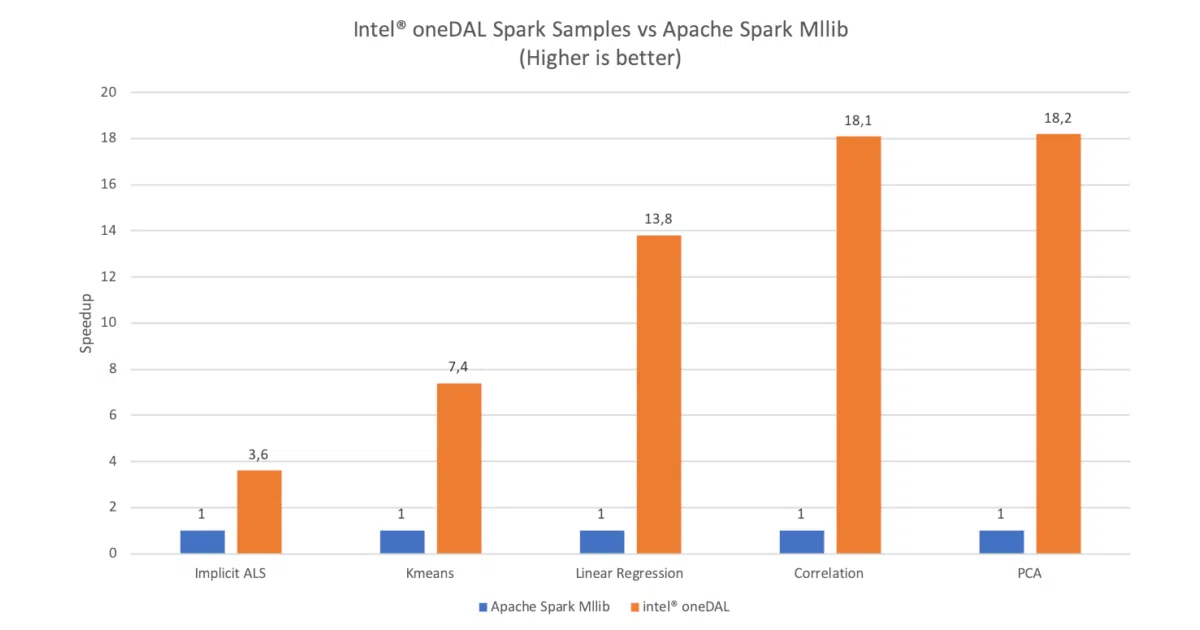
scikit-learn-intelexpatches common estimators to call oneDAL instead; the README claims this is the primary Python path - Spark acceleration: Used in OAP MLlib for 3–18× speedups over default Apache Spark MLlib (per their benchmark chart, though hardware details are dated—2019-era Xeons and AWS m5 instances)
- Distributed K-means: Strong and weak scaling charts provided; again, hardware is legacy (Xeon E5-2698 v3, 2019 software stack)
- Multiple interface generations: oneAPI interfaces (with/without SYCL), plus legacy DAAL interfaces—migration complexity depends on your starting point
- UXL Foundation governance: Part of a broader open standards push, with public specs and working groups
Caveats
- Benchmarks in the README use dated hardware and software; treat the specific multipliers as directional, not current
- The C++ API surface has accumulated interface generations (DAAL → oneAPI C++ → oneAPI DPC++); docs suggest this is navigable but not frictionless
Verdict
Worth a look if you’re already in Intel’s ecosystem, need to accelerate scikit-learn without rewriting pipelines, or want SYCL-based ML kernels for cross-platform GPU deployment. Skip it if you’re committed to PyTorch/TensorFlow-native workflows or need bleeding-edge model architectures—this is classic ML, not deep learning.
Frequently asked
- What is uxlfoundation/oneDAL?
- A C++/SYCL number-crunching engine that accelerates classic ML algorithms on CPUs, GPUs, and clusters—often without changing your Python code.
- Is oneDAL open source?
- Yes — uxlfoundation/oneDAL is open source, released under the Apache-2.0 license.
- What language is oneDAL written in?
- uxlfoundation/oneDAL is primarily written in C++.
- How popular is oneDAL?
- uxlfoundation/oneDAL has 651 stars on GitHub.
- Where can I find oneDAL?
- uxlfoundation/oneDAL is on GitHub at https://github.com/uxlfoundation/oneDAL.