tomlepaine/fast-wavenet
WaveNet inference without the exponential meltdown
A caching trick turns O(2^L) generation into O(L), making deep autoregressive audio models actually usable at inference time.
Not currently ranked — collecting fresh signals.
star history
What it does
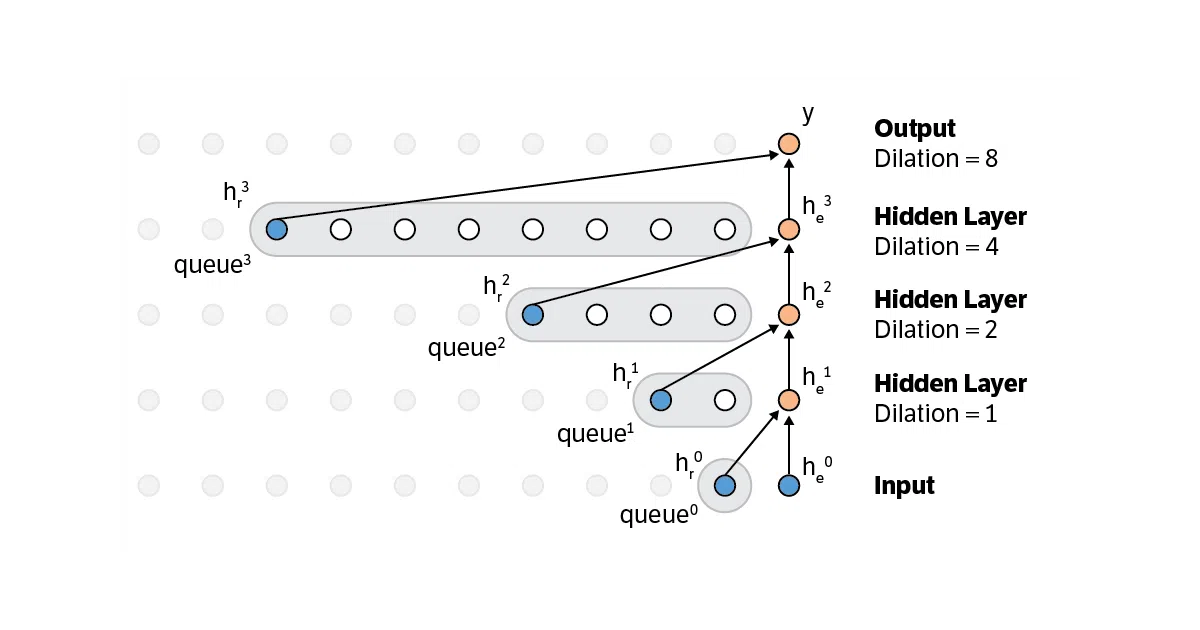
Fast-wavenet is a reference implementation of a generation-time optimization for WaveNet and similar causal dilated convolution networks. Instead of recomputing the full binary tree of convolutions for every output sample, it caches “recurrent states” per layer and reuses them via pop/push queues. The result: inference complexity drops from exponential to linear in the number of layers.
The interesting bit
The authors confirmed with DeepMind that the original WaveNet team was already doing something similar—just not writing it down. The repo’s real value is making the trick explicit and visual: binary-tree diagrams, queue mechanics, and a worked example you can adapt to any streaming causal convnet.
Key highlights
- Complexity: O(2^L) → O(L) for generation with L layers
- Works for any causal dilated CNN, not just audio (streaming classification/regression too)
- Includes timing experiments showing crossover point where caching wins over naive GPU convolution
- Accompanied by arXiv paper with full derivation
- ~1,700 stars, TensorFlow implementation
Caveats
- For small L, naive GPU convolution can still be faster due to parallelism; the win only appears at scale
- README notes this is “mostly” the algorithm description plus example code, not a full training pipeline
Verdict
Grab this if you’re shipping WaveNet-style models to production or hacking on streaming convnets. Skip it if you just want pretrained weights and a generate.py script—this is the boring-but-critical plumbing, not the demo.
Frequently asked
- What is tomlepaine/fast-wavenet?
- A caching trick turns O(2^L) generation into O(L), making deep autoregressive audio models actually usable at inference time.
- Is fast-wavenet open source?
- Yes — tomlepaine/fast-wavenet is open source, released under the GPL-3.0 license.
- What language is fast-wavenet written in?
- tomlepaine/fast-wavenet is primarily written in Python.
- How popular is fast-wavenet?
- tomlepaine/fast-wavenet has 1.8k stars on GitHub.
- Where can I find fast-wavenet?
- tomlepaine/fast-wavenet is on GitHub at https://github.com/tomlepaine/fast-wavenet.