thu-ml/TurboDiffusion
Video diffusion in 1.9 seconds on a single GPU
A distillation and attention-hacking framework that squeezes 100–200× speedups out of Wan video models without requiring a server farm.
Not currently ranked — collecting fresh signals.
star history
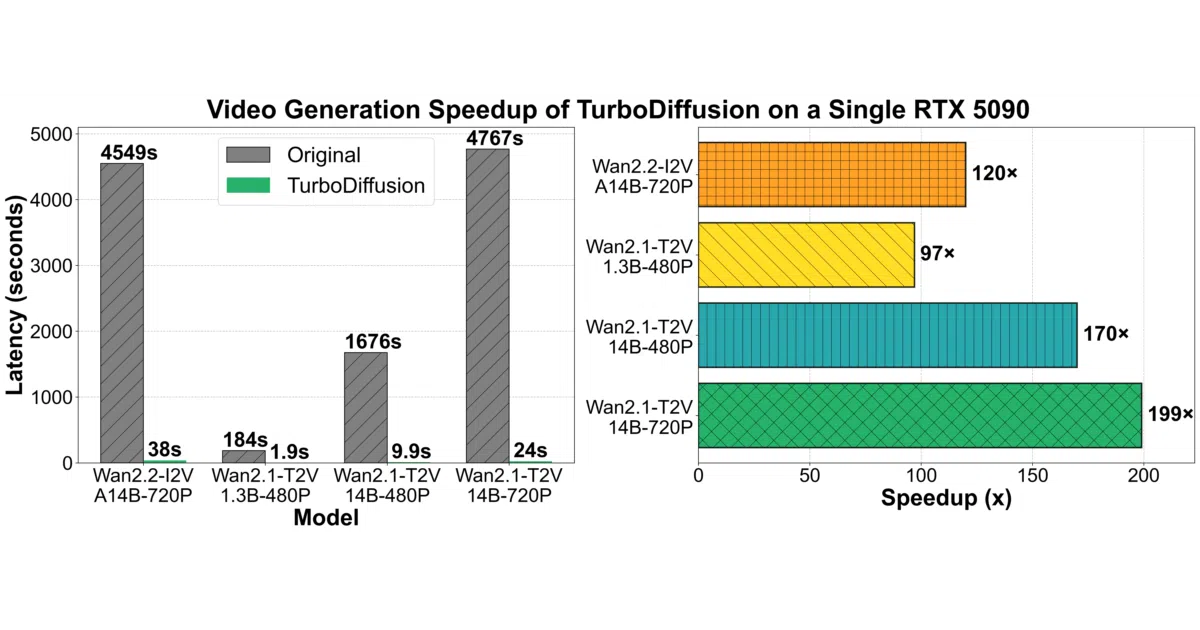
What it does TurboDiffusion is an inference acceleration stack for Wan text-to-video and image-to-video models. It combines three existing techniques—rCM timestep distillation, SageAttention, and Sparse-Linear Attention (SLA)—to cut end-to-end generation time from minutes down to seconds on a single RTX 5090. The repo provides finetuned checkpoints, inference scripts, and a terminal-based interactive server.
The interesting bit The speedup is compositional, not a single trick. rCM collapses the sampling steps (down to 1–4), while SageAttention and SLA attack the quadratic memory wall in video attention. The authors also ship quantized checkpoints for consumer GPUs and unquantized ones for H100s, which is a pragmatic split you don’t always see in research releases.
Key highlights
- Claims 184 s → 1.9 s for Wan-2.1-T2V-1.3B-480P and 4549 s → 38 s for Wan-2.2-I2V-A14B-720P on an RTX 5090
- Supports T2V (1.3B and 14B) and I2V (A14B) at 480p and 720p
- Optional SageSLA attention via a separate SpargeAttn install for even faster forward passes
- Interactive multi-turn generation in
turbodiffusion/serve/without model reload - Paper and checkpoints are explicitly marked as not yet finalized
Caveats
- Models trained only on long English prompts; short or non-English prompts need manual augmentation
torch==2.8.0recommended; newer PyTorch versions may OOM- Checkpoints and paper are still being updated, so quality and reproducibility may shift
Verdict Worth a look if you’re running Wan models locally and want to trade a small quality dice-roll for massive latency gains. Skip it if you need production-grade stability today or work primarily with short prompts.
Frequently asked
- What is thu-ml/TurboDiffusion?
- A distillation and attention-hacking framework that squeezes 100–200× speedups out of Wan video models without requiring a server farm.
- Is TurboDiffusion open source?
- Yes — thu-ml/TurboDiffusion is open source, released under the Apache-2.0 license.
- What language is TurboDiffusion written in?
- thu-ml/TurboDiffusion is primarily written in Python.
- How popular is TurboDiffusion?
- thu-ml/TurboDiffusion has 3.6k stars on GitHub.
- Where can I find TurboDiffusion?
- thu-ml/TurboDiffusion is on GitHub at https://github.com/thu-ml/TurboDiffusion.