thu-ml/SageAttention
2–5× attention speedups without the accuracy apology tour
A family of drop-in CUDA kernels that quantize transformer attention to INT8 and FP8 to accelerate inference on modern NVIDIA GPUs while claiming no end-to-end quality loss.
Not currently ranked — collecting fresh signals.
star history
What it does
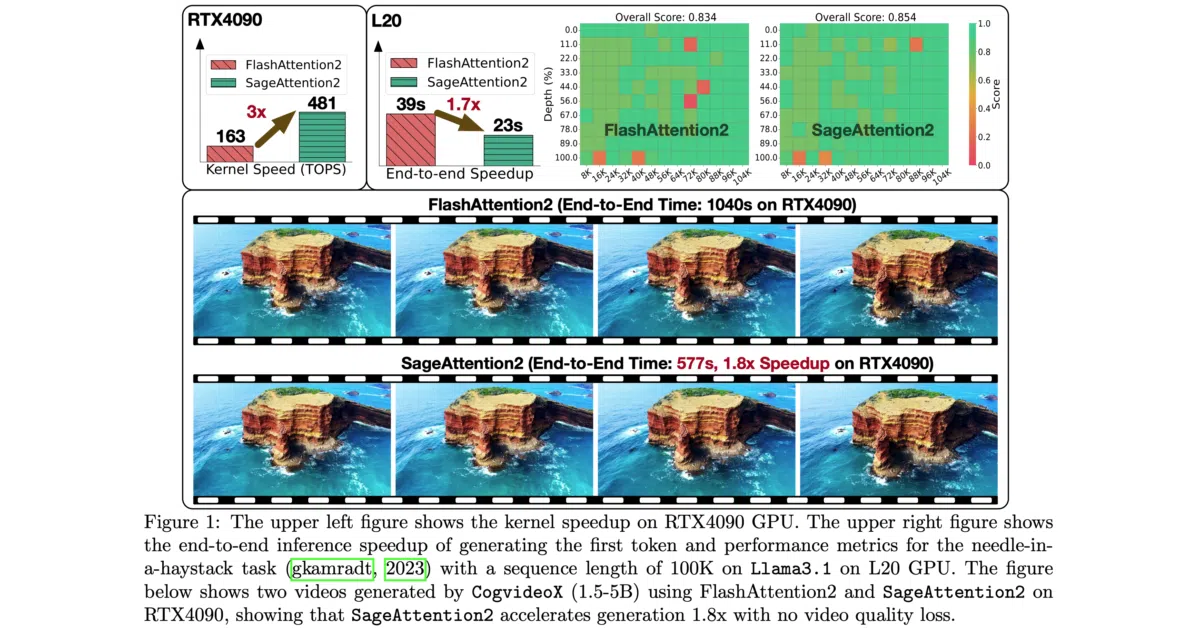
SageAttention replaces standard scaled_dot_product_attention with heavily quantized CUDA kernels—INT8 for the QK^T matmul and FP8 or FP16 for the PV matmul—targeting Ampere through Blackwell GPUs. The project claims 2–5× speedups over FlashAttention across language, image, and video models without degrading end-to-end metrics, and exposes a single sageattn entrypoint that auto-selects the best kernel for the hardware.
The interesting bit Instead of treating quantization as a blunt performance hack, the authors apply outlier smoothing and per-thread quantization to keep matmuls stable, then use a two-level accumulation strategy to recover precision inside FP8 tensor cores. The result is a kernel family that the authors say matches FlashAttention3-FP8 on raw speed on Hopper while preserving noticeably better accuracy.
Key highlights
- Auto-selecting
sageattnAPI picks the optimal INT8/FP8/FP16 kernel for Ampere, Ada, Hopper, and Blackwell GPUs - Claims 2–5× speedup over FlashAttention with no end-to-end accuracy loss on LLMs, image, and video diffusion models
- Two-level accumulation for PV matmuls to recover precision when using FP8 MMA and WGMMA
- Supports
torch.compile, distributed inference, group-query attention, and variable sequence lengths within a batch - SageAttention3 adds FP4 microscaling for inference and experiments with 8-bit training, though the authors still recommend SageAttention2 for precision-sensitive work
Caveats
- The simple
F.scaled_dot_product_attention = sageattnmonkey-patch fails on many models; image and video transformers typically require surgical replacement inside the DiT attention class - SageAttention3 is newer and faster, but the authors explicitly recommend SageAttention2 for precision-sensitive applications
- Hardware support is fragmented: Blackwell and SageAttention2++ require CUDA ≥12.8, while FP8 on Hopper needs ≥12.3 and Ampere needs ≥12.0
Verdict Worth benchmarking if you serve LLMs or diffusion models on modern NVIDIA hardware and need to shave time off the attention bottleneck. Skip it if you are on non-NVIDIA GPUs, need guaranteed bit-exact reproducibility, or want a one-line swap that works blindly across every model architecture.
Frequently asked
- What is thu-ml/SageAttention?
- A family of drop-in CUDA kernels that quantize transformer attention to INT8 and FP8 to accelerate inference on modern NVIDIA GPUs while claiming no end-to-end quality loss.
- Is SageAttention open source?
- Yes — thu-ml/SageAttention is open source, released under the Apache-2.0 license.
- What language is SageAttention written in?
- thu-ml/SageAttention is primarily written in Cuda.
- How popular is SageAttention?
- thu-ml/SageAttention has 3.5k stars on GitHub.
- Where can I find SageAttention?
- thu-ml/SageAttention is on GitHub at https://github.com/thu-ml/SageAttention.