ternaus/robot-surgery-segmentation
Teaching robots to see inside your insides
A 2017 competition-winning approach to pixel-precise surgical instrument segmentation, later refined with pre-trained encoder tricks.
Not currently ranked — collecting fresh signals.
star history
What it does
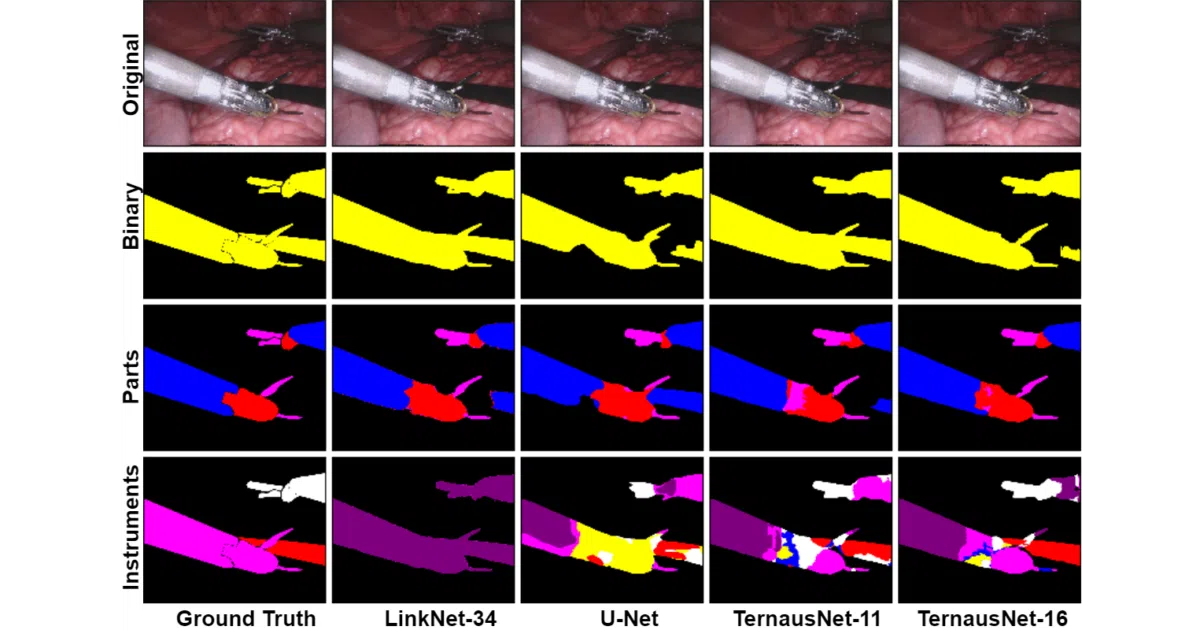
This repo contains the winning solution (and subsequent improvements) for the MICCAI 2017 Robotic Instrument Segmentation challenge. It trains deep networks to label every pixel in endoscopic surgery video as either background, instrument, or specific instrument parts — useful for tracking where robot-assisted surgical tools actually are inside a patient.
The interesting bit
The authors took the classic U-Net and swapped in pre-trained encoders — VGG11/VGG16 for their “TernausNet” variants, ResNet34 for a LinkNet version — which boosted performance without reinventing the decoder wheel. It’s a pragmatic reminder that in medical imaging, transfer learning from ImageNet often beats training from scratch, even when your data is laparoscopic guts instead of cats.
Key highlights
- Three segmentation tasks: binary (instrument vs. background), parts (shaft/wrist/clasper), and full 7-class instrument identification
- Best binary IoU: 0.836 (TernausNet-16), beating prior literature at the time
- Multi-class instrument segmentation struggles (IoU 0.346 for 7 classes) — small dataset, rare instrument appearances
- Includes pre-trained weights, 4-fold cross-validation setup, and inference scripts
- Dependencies frozen to PyTorch 0.4.0 era (Python 3.6, old OpenCV)
Caveats
- The README has a charming number of typos (“wining,” “folloing,” “unindormative”) and the dependency stack is several years stale
- Dataset is tiny by modern standards: 8 × 225-frame training sequences, with frames correlated within each video
- No clear license specified in the provided sources
Verdict
Worth studying if you’re building surgical computer vision systems or need a worked example of U-Net encoder surgery. Skip if you want production-ready, maintained code — this is a competition artifact with academic dependencies.
Frequently asked
- What is ternaus/robot-surgery-segmentation?
- A 2017 competition-winning approach to pixel-precise surgical instrument segmentation, later refined with pre-trained encoder tricks.
- Is robot-surgery-segmentation open source?
- Yes — ternaus/robot-surgery-segmentation is open source, released under the MIT license.
- What language is robot-surgery-segmentation written in?
- ternaus/robot-surgery-segmentation is primarily written in Jupyter Notebook.
- How popular is robot-surgery-segmentation?
- ternaus/robot-surgery-segmentation has 638 stars on GitHub.
- Where can I find robot-surgery-segmentation?
- ternaus/robot-surgery-segmentation is on GitHub at https://github.com/ternaus/robot-surgery-segmentation.