tensorflow/tfx
Google's ML pipeline glue, now with extra dependencies
TFX wires TensorFlow training into production pipelines, then hands you a compatibility matrix that reads like a software bill of materials.
Not currently ranked — collecting fresh signals.
star history
What it does
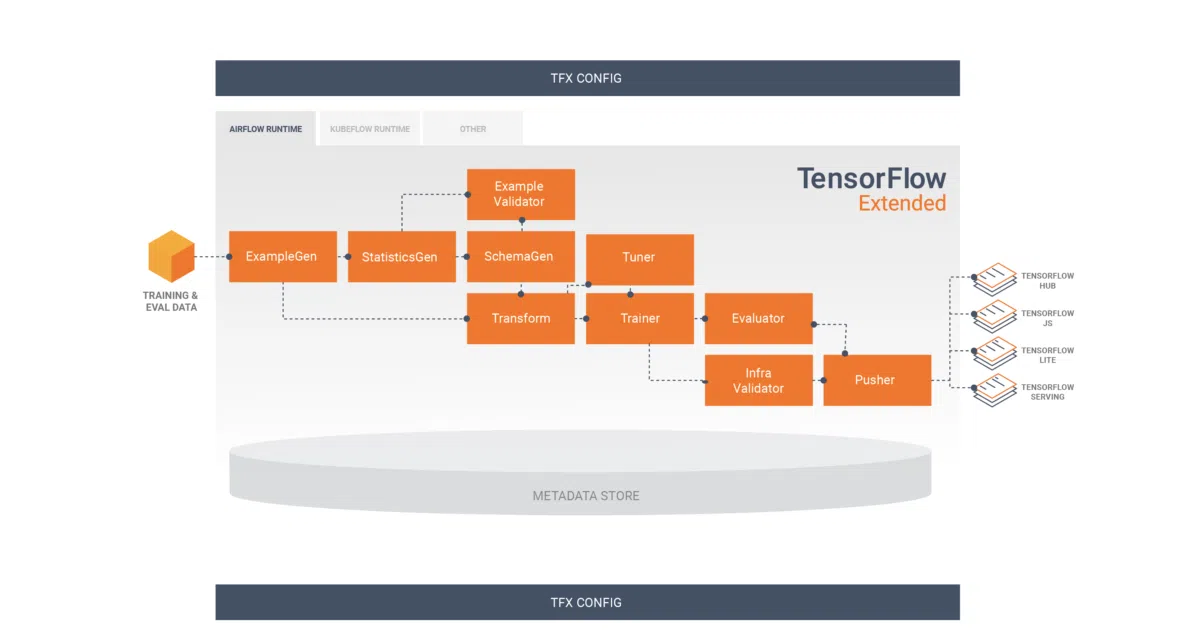
TFX is Google’s open-sourced framework for building production ML pipelines on top of TensorFlow. It provides pre-built components for the usual suspects—data validation, transformation, training, evaluation—then orchestrates them through Apache Airflow or Kubeflow Pipelines. Every component run gets logged to an ML Metadata backend, which means you can trace lineage, resume from checkpoints, or figure out which data version broke your model last Tuesday.
The interesting bit
The metadata layer is the quiet workhorse. Most pipeline tools treat provenance as an afterthought; TFX bakes it in from the start, using ML Metadata to track artifacts, executions, and configurations across runs. That makes warmstarting and experiment tracking structural features, not bolt-ons.
Key highlights
- Component-based pipeline framework with configurable stages for data ingestion through model serving
- Native orchestration support for Apache Airflow and Kubeflow Pipelines
- Built-in ML Metadata integration for artifact lineage and run history
- Extensible: both components and orchestrator integrations can be customized
- Includes a worked example (Chicago Taxi pipeline) for getting oriented
Caveats
- Dependency matrix is extensive and tightly pinned; the README compatibility table spans 11 packages with version lockstep requirements
- Python support currently limited to 3.9–3.10 for recent releases
- “Google-production-scale” in the description; actual resource requirements for that scale are unspecified
Verdict
Worth evaluating if you’re already committed to TensorFlow and need auditability across pipeline runs. Probably overkill if your model retrains once a month and your current cron job isn’t broken.
Frequently asked
- What is tensorflow/tfx?
- TFX wires TensorFlow training into production pipelines, then hands you a compatibility matrix that reads like a software bill of materials.
- Is tfx open source?
- Yes — tensorflow/tfx is open source, released under the Apache-2.0 license.
- What language is tfx written in?
- tensorflow/tfx is primarily written in Python.
- How popular is tfx?
- tensorflow/tfx has 2.2k stars on GitHub.
- Where can I find tfx?
- tensorflow/tfx is on GitHub at https://github.com/tensorflow/tfx.