tech-srl/code2vec
Teaching neural networks to read code like a senior dev skimming a PR
An official TensorFlow implementation of the POPL'2019 paper that learns to predict method names from Java source by treating AST paths as first-class citizens.
Not currently ranked — collecting fresh signals.
star history
What it does
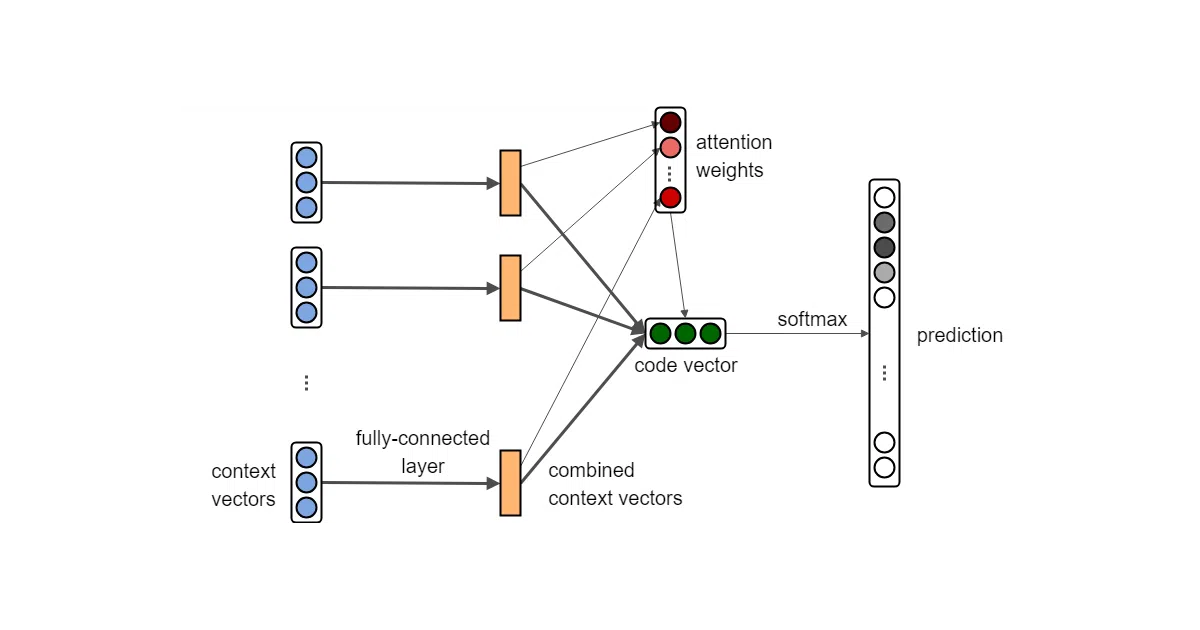
code2vec trains a neural network to predict Java method names by learning from the structural paths between tokens in abstract syntax trees. Feed it ~14 million preprocessed Java methods and it distills syntactic patterns into distributed vector representations — essentially turning code structure into something a model can embed and compare.
The repo ships with two implementations (pure TensorFlow and tf.keras), pre-trained models, and a 32GB preprocessed dataset so you can skip the data wrangling and start experimenting.
The interesting bit
Instead of treating code as flat text, the model samples paths between terminal nodes in an AST and learns which structural routes matter most for naming a method. It’s word2vec’s “king - man + woman” logic applied to program graphs rather than sentences.
Key highlights
- Official POPL'2019 implementation with both TensorFlow and Keras model variants
- Pre-trained on 14M Java methods; downloadable models in “released” (1.4GB, inference-only) and trainable (3.5GB) flavors
- Network is language-agnostic — extendable beyond Java by swapping the AST parser
- Online demo at code2vec.org for quick manual testing
- Active research lineage: authors later published code2seq (ICLR'2019), structural code generation, and adversarial attacks on code models
Caveats
- Requires TensorFlow 2.0.0 and CUDA 10.0 specifically; newer stacks need careful version pinning
- Training demands real GPU horsepower: ~50 min/epoch on V100, ~4 hours on K80
- Manual early stopping: you kill the process when validation F1 plateaus, then pick your best checkpoint
Verdict Worth grabbing if you’re doing research on code representation or need a solid baseline for method-name prediction. Skip it if you want out-of-the-box support for languages beyond Java without writing your own preprocessor, or if you’re allergic to legacy CUDA toolchains.
Frequently asked
- What is tech-srl/code2vec?
- An official TensorFlow implementation of the POPL'2019 paper that learns to predict method names from Java source by treating AST paths as first-class citizens.
- Is code2vec open source?
- Yes — tech-srl/code2vec is open source, released under the MIT license.
- What language is code2vec written in?
- tech-srl/code2vec is primarily written in Python.
- How popular is code2vec?
- tech-srl/code2vec has 1.1k stars on GitHub.
- Where can I find code2vec?
- tech-srl/code2vec is on GitHub at https://github.com/tech-srl/code2vec.