taco-group/SparkVSR
Let users paint keyframes, let AI fill the rest
SparkVSR turns sparse, user-corrected frames into full video super-resolution without the black-box problem.
Not currently ranked — collecting fresh signals.
star history
What it does
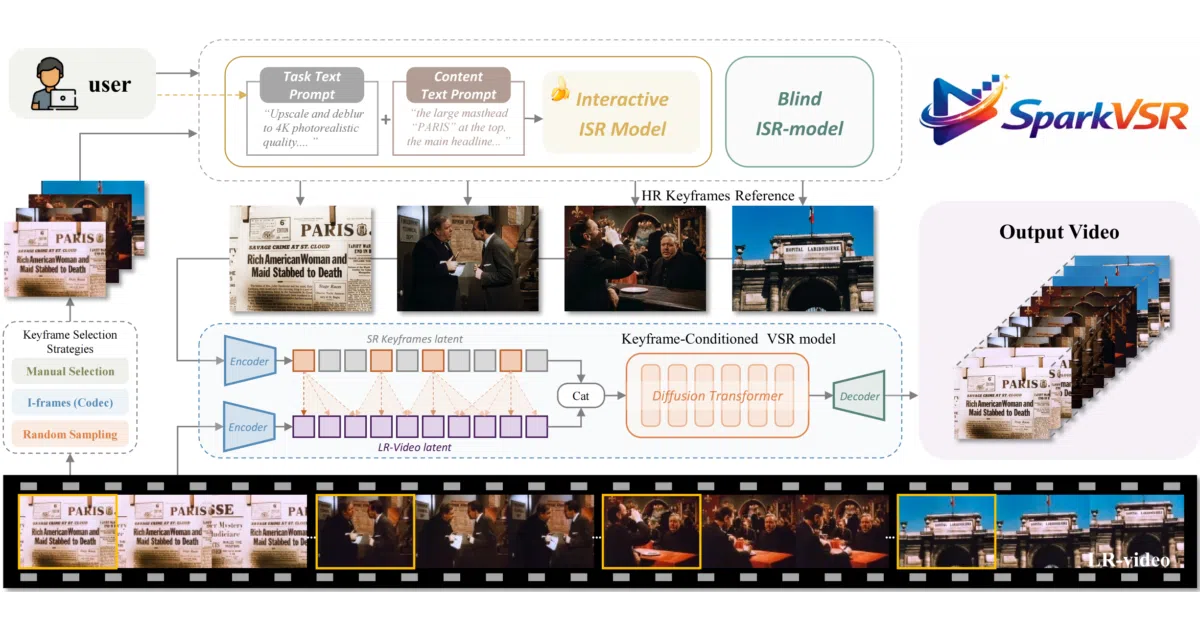
SparkVSR is a video super-resolution system built on CogVideoX1.5-5B-I2V that lets you manually fix up a few keyframes with any image SR model you like, then propagates those corrections across the entire video. It stays anchored to the original low-res motion, so you don’t get drifting hallucinations.
The interesting bit
The two-stage training is the actual machinery: Stage 1 fuses low-res video latents with sparse high-res keyframe latents in latent space for cross-frame propagation, then Stage 2 refines perceptual details back in pixel space. There’s also a reference-free guidance mechanism that gracefully degrades to blind SR when your keyframes are missing or garbage — no hard failure mode.
Key highlights
- Built on CogVideoX1.5-5B-I2V; weights and ComfyUI node both released
- Three inference modes: API-driven (
nano-banana-pro), local PiSA-SR references, or pure blind SR fallback - Flexible keyframe selection: manual, codec I-frame extraction, or random sampling
- Claims up to 24.6% CLIP-IQA, 21.8% DOVER, 5.6% MUSIQ improvement over baselines (per paper)
- Generalizes out-of-the-box to old-film restoration and video style transfer
Caveats
- Training demands 4×A100 GPUs; this is not a hobbyist setup
- The README’s benchmark percentages come from the paper, not independently verifiable in the repo
- Stage-1 checkpoint is explicitly not for inference; easy to grab the wrong weights
Verdict
Video restoration researchers and VFX pipelines that need human-in-the-loop control should look here. If you just want one-click upscaling, the complexity is overkill — use a simpler VSR model.
Frequently asked
- What is taco-group/SparkVSR?
- SparkVSR turns sparse, user-corrected frames into full video super-resolution without the black-box problem.
- Is SparkVSR open source?
- Yes — taco-group/SparkVSR is open source, released under the Apache-2.0 license.
- What language is SparkVSR written in?
- taco-group/SparkVSR is primarily written in Python.
- How popular is SparkVSR?
- taco-group/SparkVSR has 691 stars on GitHub.
- Where can I find SparkVSR?
- taco-group/SparkVSR is on GitHub at https://github.com/taco-group/SparkVSR.