szilard/benchm-ml
Benchmarking ML libraries: where the fast survive
A no-nonsense shootout of open-source ML implementations on real hardware, measuring what actually matters: can it finish before the RAM runs out?
Not currently ranked — collecting fresh signals.
star history
What it does
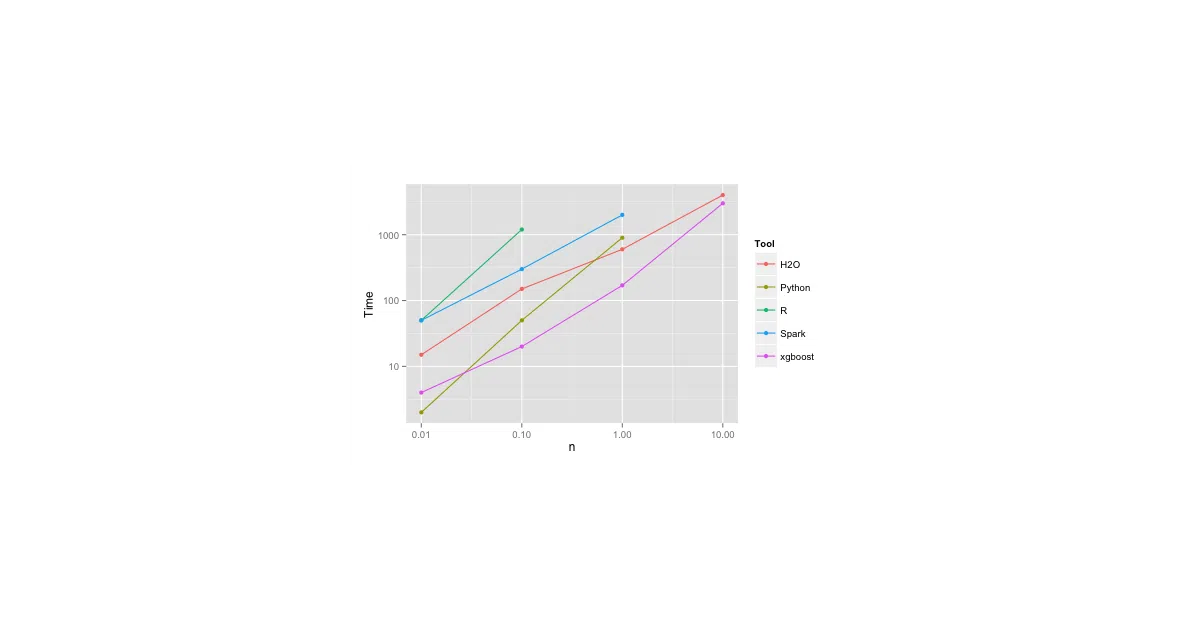
This repo benchmarks popular open-source ML libraries—R packages, Python scikit-learn, H2O, xgboost, Spark MLlib, Vowpal Wabbit—on a concrete task: binary classification of flight delays using 10K to 10M rows and ~1K features. It tracks training time, peak RAM, and AUC across linear models, random forests, boosting, and deep neural nets. The author ran everything on AWS EC2 instances (mostly c3.8xlarge, 32 cores, 60GB RAM) and published the raw numbers.
The interesting bit
The benchmark’s real value is its honesty. The author openly calls it “simple/limited/incomplete,” quotes George Box (“all benchmarks are wrong, but some are useful”), and notes that much of the work dates to 2015. The most striking finding: a random forest on 1% of the data beats a linear model on 100% of the data—contradicting the “more data beats better algorithms” mantra for this particular dense, non-sparse dataset.
Key highlights
- R’s
randomForestpackage crashes on 1M rows; Python scikit-learn crashes on 10M rows without 250GB RAM - H2O and Vowpal Wabbit are the memory-efficiency standouts for linear models; VW needs only one observation in memory at a time
- xgboost trains random forests faster and leaner than most: 170 seconds, 2GB RAM at 1M rows vs. H2O’s 600 seconds, 5GB
- The author later abandoned updating this benchmark in favor of a Docker-based successor focused solely on GBM performance
Caveats
- Most results are from 2015; library versions have evolved significantly (the author points to a newer GBM-only benchmark instead)
- Deep learning results exist but are barely detailed in the truncated README
- The “no missing data, limited cardinality categoricals” scope means sparse-text or high-cardinality problems are out of scope
Verdict
Worth a skim if you’re choosing between H2O, xgboost, and Spark for tabular binary classification on single-node hardware. Skip it if you need current numbers—the author explicitly directs readers to their newer GBM-perf project for modern, reproducible comparisons.
Frequently asked
- What is szilard/benchm-ml?
- A no-nonsense shootout of open-source ML implementations on real hardware, measuring what actually matters: can it finish before the RAM runs out?
- Is benchm-ml open source?
- Yes — szilard/benchm-ml is open source, released under the MIT license.
- What language is benchm-ml written in?
- szilard/benchm-ml is primarily written in R.
- How popular is benchm-ml?
- szilard/benchm-ml has 1.9k stars on GitHub.
- Where can I find benchm-ml?
- szilard/benchm-ml is on GitHub at https://github.com/szilard/benchm-ml.