synesthesiam/opentts
One Docker container, 27 languages, eight TTS engines
OpenTTS unifies a zoo of open-source speech synthesizers behind a single HTTP API and a subset of SSML.
Not currently ranked — collecting fresh signals.
star history
What it does
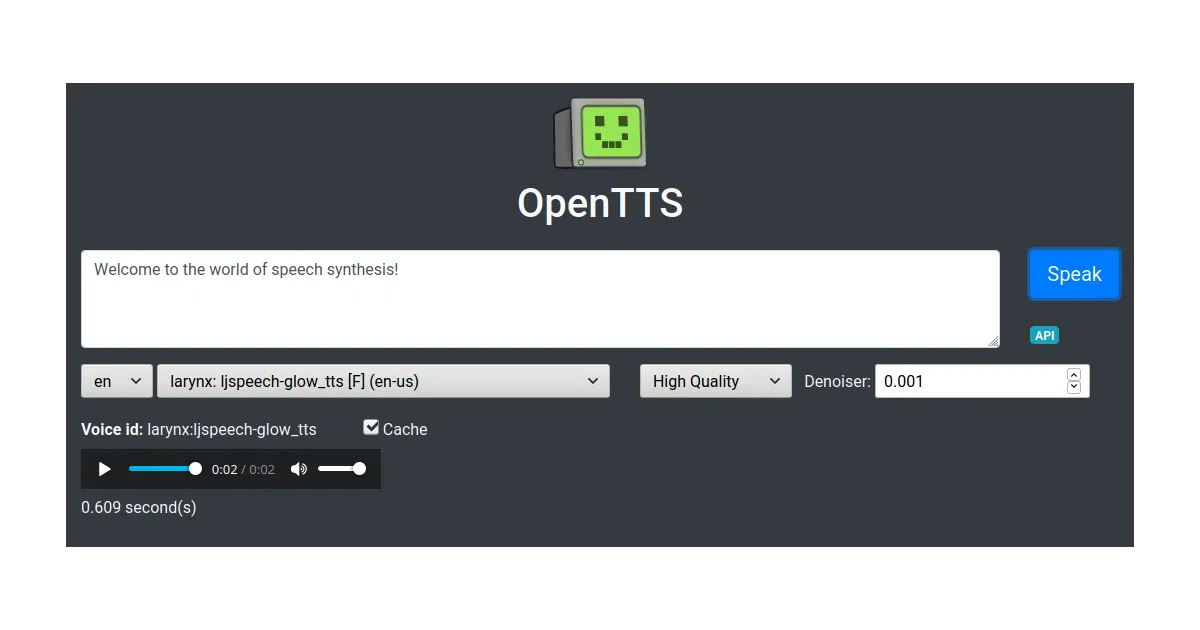
OpenTTS is a Python server that wraps eight different open-source text-to-speech systems — from neural models like Larynx and Coqui-TTS to classic rule-based engines like Festival and eSpeak — and exposes them through one HTTP API. You request a voice by name (e.g., glow-speak:en-us_mary_ann or coqui-tts:en_vctk#p228), and the server returns WAV audio. It also supports a practical subset of SSML, including voice switching mid-document, breaks, and language tags.
The interesting bit The SSML implementation is where the glue code gets clever: you can switch TTS engines within the same document, jumping from a neural English voice to a robotic-but-functional Swahili voice, or mixing German, Japanese, and Arabic sentences. The server also mimics MaryTTS’s endpoint, so existing integrations can swap in OpenTTS without code changes.
Key highlights
- Docker-first deployment with per-language images (
synesthesiam/opentts:en,:de,:all, etc.) - WAV caching with optional disk mount for repeated phrases
- Voice quality tiers (
high/medium/low) for Larynx/Glow-Speak, useful on Raspberry Pi - Multi-speaker model support via
#speaker_idsyntax (currently Coqui-TTS English) - Web UI and OpenAPI test page at
localhost:5500
Caveats
- Build-from-source requires re-initializing QEMU/docker buildx after every reboot (documented, but annoying)
- Some Festival voices use legacy ISO-8859 encodings; Russian requires automatic transliteration to Latin
- eSpeak is included by default and explicitly described as “robotic”; use
--no-espeakto exclude it
Verdict Worth a look if you’re running home automation, accessibility tools, or any project that needs offline TTS across multiple languages without managing eight separate toolchains. Skip it if you need production-grade cloud voices or deep SSML control — this is a pragmatic unification layer, not a voice quality breakthrough.
Frequently asked
- What is synesthesiam/opentts?
- OpenTTS unifies a zoo of open-source speech synthesizers behind a single HTTP API and a subset of SSML.
- Is opentts open source?
- Yes — synesthesiam/opentts is open source, released under the MIT license.
- What language is opentts written in?
- synesthesiam/opentts is primarily written in Python.
- How popular is opentts?
- synesthesiam/opentts has 1.1k stars on GitHub.
- Where can I find opentts?
- synesthesiam/opentts is on GitHub at https://github.com/synesthesiam/opentts.