subho406/OmniNet
One Transformer to caption, parse, and answer questions
OmniNet trains a single model on vision, language, and video tasks simultaneously using shared spatio-temporal representations.
Not currently ranked — collecting fresh signals.
star history
What it does
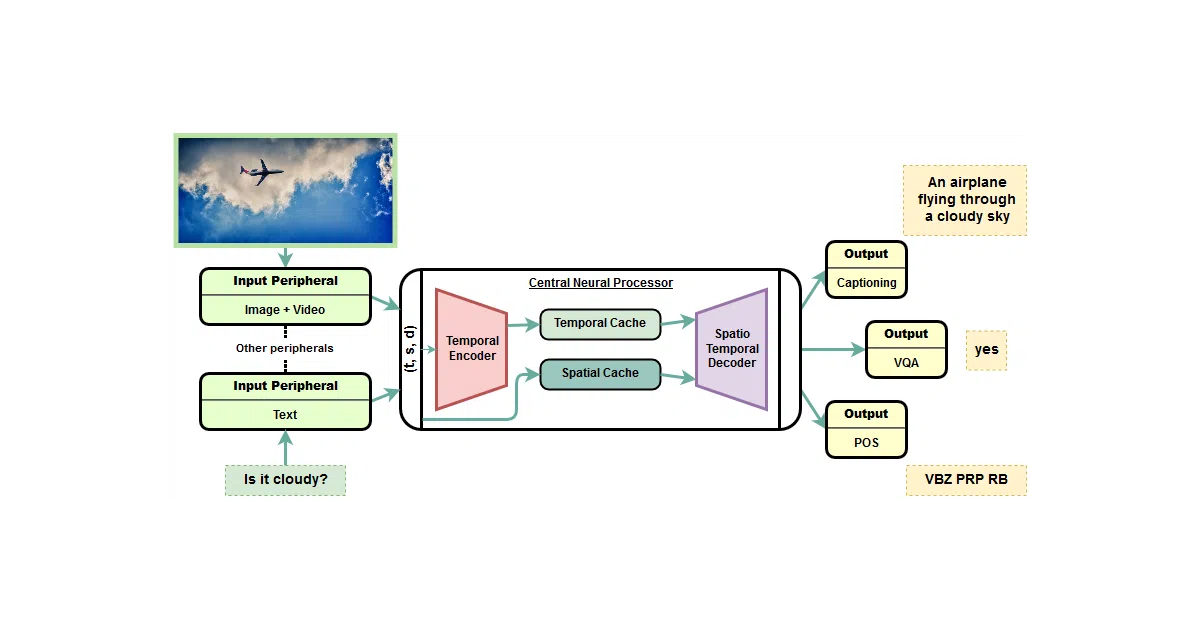
OmniNet is a multi-modal, multi-task Transformer. Domain-specific “neural peripherals” encode text, images, or video into a common representation, then feed a central Transformer encoder-decoder. One model instance handles part-of-speech tagging, image captioning, visual question answering, and video activity recognition—trained jointly, not as separate pipelines.
The interesting bit
The architecture claims zero-shot transfer across modalities: a model never trained on video captioning or video QA can still generate captions and answer questions about video, because the central processor learns shared spatio-temporal representations. The README shows it guessing “a person riding a horse on a beach” from raw video, and answering “brown” for horse color—though it notes these results are “still experimental and not always meaningful.”
Key highlights
- Single Pytorch codebase with pretrained models for each task and a combined multi-task checkpoint
- Hogwild multi-GPU training: assign different tasks to different GPUs with independent batch sizes
- Prediction script works across all four tasks with the same model file; swap
--text,--image, or--videoflags - Pretrained models hosted on Google Cloud Storage; reproduction data available via
scripts/init_setup.py - Apache 2.0 license
Caveats
- Requires Linux, NVIDIA GPU with 8GB+ VRAM, and Anaconda; no Windows or CPU-only path mentioned
- PENN POS tagging dataset must be downloaded and preprocessed manually; the automated script skips it
- Prediction currently uses greedy decoding only; beam search is listed as future work
- Zero-shot results are explicitly flagged as experimental
Verdict
Worth a look if you’re researching unified multi-modal architectures or need a baseline for joint vision-language training. Skip it if you want production-ready video understanding or a lightweight model that runs on modest hardware.
Frequently asked
- What is subho406/OmniNet?
- OmniNet trains a single model on vision, language, and video tasks simultaneously using shared spatio-temporal representations.
- Is OmniNet open source?
- Yes — subho406/OmniNet is an open-source project tracked on heatdrop.
- What language is OmniNet written in?
- subho406/OmniNet is primarily written in Python.
- How popular is OmniNet?
- subho406/OmniNet has 514 stars on GitHub.
- Where can I find OmniNet?
- subho406/OmniNet is on GitHub at https://github.com/subho406/OmniNet.