sierra-research/tau2-bench
A stress test for chatbots that actually talk back
τ-bench simulates realistic customer service scenarios to measure whether your agent can follow policy, use tools, and not infuriate a simulated human.
Velocity · 7d
+7.6
★ / day
Trend
→steady
star history
What it does
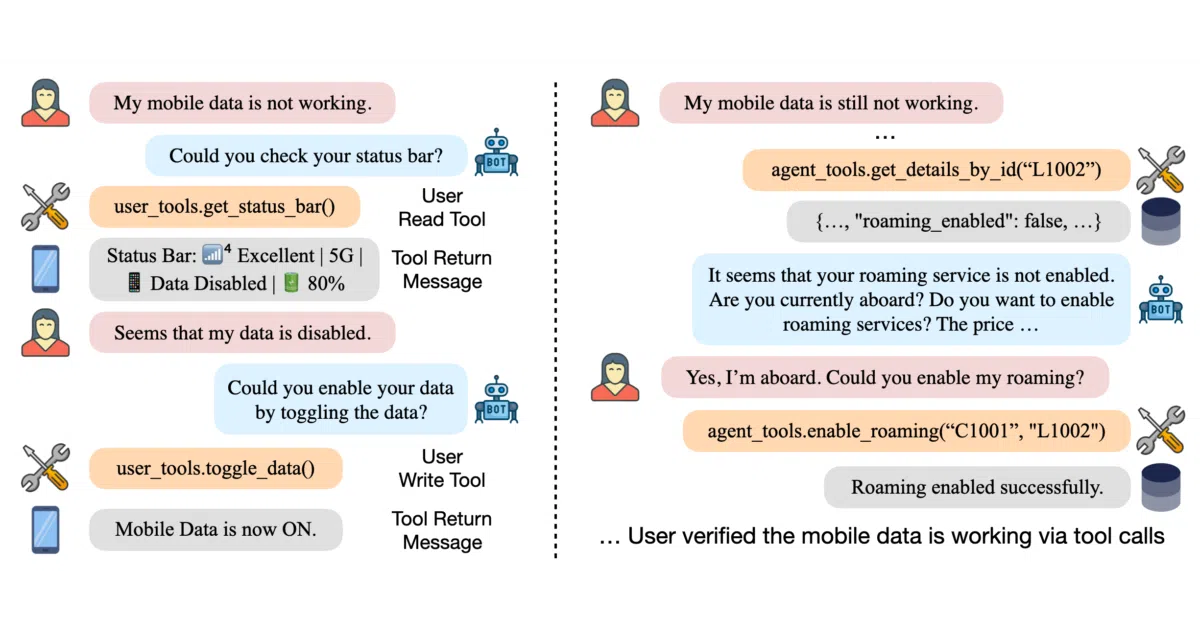
τ-bench is a simulation framework that pits customer service agents against simulated users in domains like airline, retail, telecom, and banking. Each scenario gives the agent a policy to follow, tools to call, and a user who may or may not be cooperative. The framework scores whether the agent completes the task correctly without violating constraints.
The latest τ³ release adds multimodal evaluation: full-duplex voice through realtime APIs (OpenAI, Gemini, xAI), a knowledge-retrieval banking domain with configurable RAG pipelines, and 75+ task fixes based on a separate research project that found small action errors cascading into big failures.
The interesting bit
Most agent benchmarks treat conversation as turn-based text. τ-bench will also pipe actual audio through realtime providers, letting you evaluate whether your voice agent can handle interruptions, pauses, and the general chaos of human speech. There’s even a Gymnasium interface if you want to train RL agents to be better at pretending to care about your lost luggage.
Key highlights
- Five domains including a new
banking_knowledgeretrieval task with embeddings and sandboxed search - Voice evaluation via native realtime adapters, not just text-to-speech bolted on
- Live leaderboard at taubench.com with separate tracks for text, voice, and knowledge
- 75+ task quality fixes removing impossible constraints and ambiguous instructions
- Modular extras: install voice, knowledge, gym, or dev dependencies as needed
Caveats
- Requires Python 3.12+ and
uv; upgrading from τ² means refactoring some internal API calls - Voice mode needs system-level audio dependencies (PortAudio, FFmpeg) and real API keys
- The “user” is itself an LLM, so you’re measuring whether one language model frustrates another
Verdict
Worth a look if you’re building customer-facing agents and need more realism than static Q&A datasets. Skip it if your use case is far from conversational support or you’re allergic to LLM-as-judge evaluation patterns.
Frequently asked
- What is sierra-research/tau2-bench?
- τ-bench simulates realistic customer service scenarios to measure whether your agent can follow policy, use tools, and not infuriate a simulated human.
- Is tau2-bench open source?
- Yes — sierra-research/tau2-bench is open source, released under the MIT license.
- What language is tau2-bench written in?
- sierra-research/tau2-bench is primarily written in Python.
- How popular is tau2-bench?
- sierra-research/tau2-bench has 1.6k stars on GitHub and is currently holding steady.
- Where can I find tau2-bench?
- sierra-research/tau2-bench is on GitHub at https://github.com/sierra-research/tau2-bench.