sgl-project/mini-sglang
LLM serving deconstructed into 5,000 lines of Python
It exists so researchers and developers can read a production-grade LLM inference engine in an afternoon instead of wading through a monolithic codebase.
Velocity · 7d
+7.3
★ / day
Trend
↗accelerating
star history
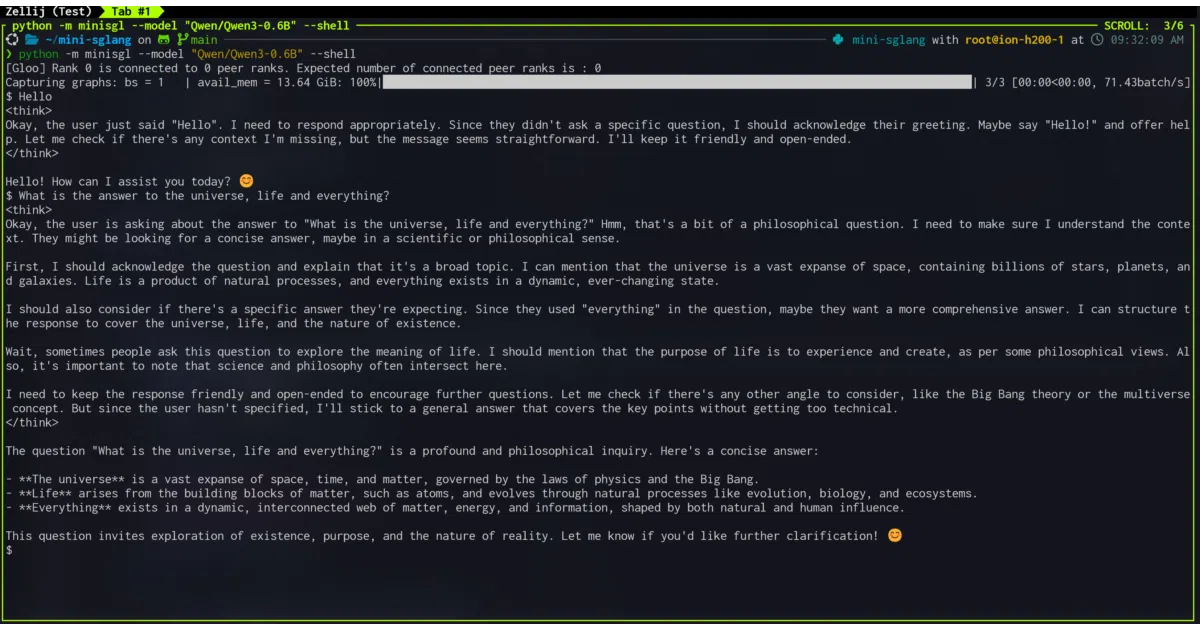
What it does\n\nMini-SGLang is a compact reimplementation of the SGLang inference framework, weighing roughly 5,000 lines of Python. It functions as a fully capable LLM serving engine—complete with an OpenAI-compatible API server, interactive shell mode, and tensor parallelism—while remaining small enough to serve as a readable reference implementation. The project targets Linux on x86_64 and aarch64, and relies on JIT-compiled CUDA kernels through FlashAttention and FlashInfer.\n\nThe interesting bit\n\nThe real product is transparency. Most high-performance serving stacks are sprawling codebases where optimizations are buried under abstractions; Mini-SGLang keeps the same tricks—radix cache prefix reuse, chunked prefill, overlap scheduling—but leaves them in a clean, modular, fully type-annotated layout that you can trace with a text editor.\n\nKey highlights\n\n* ~5,000 lines of Python intended to be read and modified, not merely executed.\n* Ships with advanced optimizations usually found in heavyweight engines: Radix Cache, chunked prefill, overlap scheduling, and tensor parallelism across multiple GPUs.\n* Integrates FlashAttention and FlashInfer for kernel efficiency.\n* Benchmarks against the full SGLang stack on H200 hardware, though specific throughput numbers are presented only in charts.\n* Supports an interactive shell mode (--shell) and standard OpenAI-compatible API serving.\n\nCaveats\n\n* Linux only; Windows and macOS are explicitly unsupported due to Linux-specific CUDA kernel dependencies (sgl-kernel, flashinfer).\n* The README claims "state-of-the-art throughput and latency" but presents results only as benchmark charts without extractable numerical data.\n\nVerdict\n\nGrab this if you are a researcher or systems engineer who wants to understand how modern LLM serving works under the hood without debugging a million-line codebase. Skip it if you need cross-platform support or a battle-hardened, fully featured production server out of the box.
Frequently asked
- What is sgl-project/mini-sglang?
- It exists so researchers and developers can read a production-grade LLM inference engine in an afternoon instead of wading through a monolithic codebase.
- Is mini-sglang open source?
- Yes — sgl-project/mini-sglang is open source, released under the MIT license.
- What language is mini-sglang written in?
- sgl-project/mini-sglang is primarily written in Python.
- How popular is mini-sglang?
- sgl-project/mini-sglang has 4.6k stars on GitHub and is currently accelerating.
- Where can I find mini-sglang?
- sgl-project/mini-sglang is on GitHub at https://github.com/sgl-project/mini-sglang.