scofield7419/sequence-labeling-BiLSTM-CRF
A 2016 classic, frozen in TensorFlow 1.x amber
A configurable, beginner-friendly BiLSTM-CRF implementation for sequence labeling that hasn't moved on from TensorFlow 1.10.
Not currently ranked — collecting fresh signals.
star history
What it does
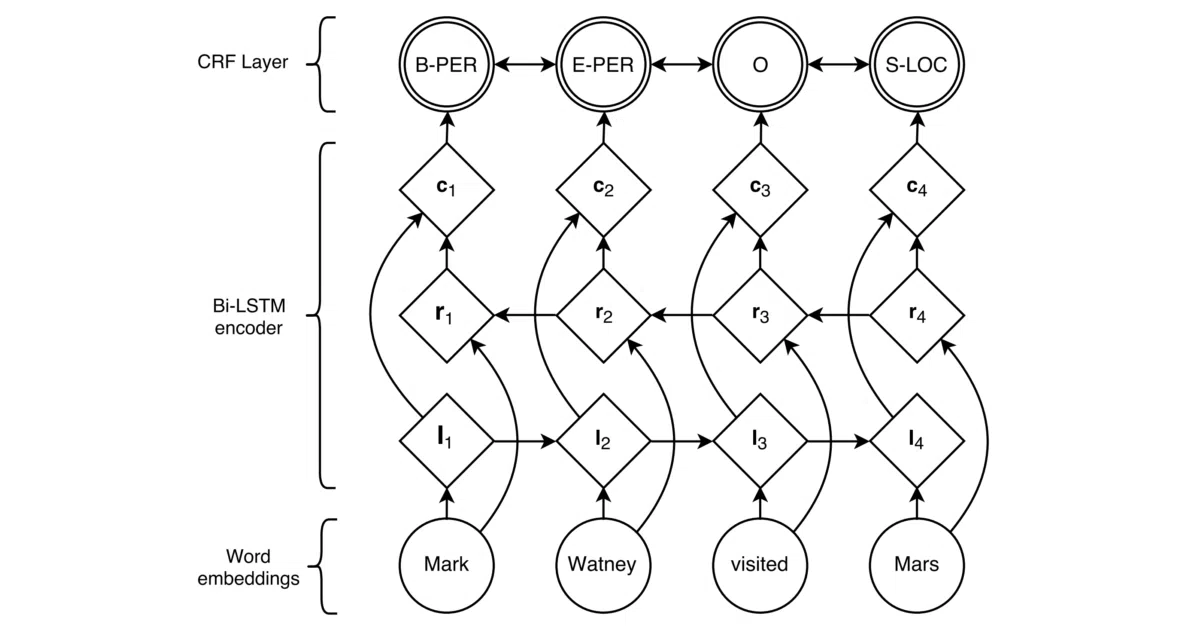
Trains and runs a BiLSTM-CRF model for sequence labeling tasks—NER, POS tagging, chunking, Chinese word segmentation, and others. You feed it token sequences with BIO or BIESO labels; it learns to predict label sequences via a bidirectional LSTM encoder plus CRF decoder. The repo wraps this in a configurable Python system with train/test/interactive/api-service modes and a small Django web demo.
The interesting bit
The project is deliberately built as a learning scaffold: everything lives in a single config file (system.config), the code is modularized into clear engines/ classes (BiLSTM_CRFs, DataManager, Configer), and the README walks through each step with screenshots. It’s less a framework than a well-commented reference implementation you can dissect and patch.
Key highlights
- Supports both word-level and char-level embeddings, with optional self-attention
- Labeling schemes configurable: BIO/BIESO, with or without suffix types (PER, LOC, ORG, etc.)
- Multiple run modes: train, test, interactive CLI prediction, and a Django web app/API service
- Object-oriented structure intended to be “easy for DIY” modifications
- Includes example datasets and a handbook (
HandBook.md) for usage details
Caveats
- Locked to TensorFlow 1.8+ and Python 3.5/3.6; the
pip install BiLSTM-CRFoption is marked “TODO” and appears unfinished - The “Option B” package install is unimplemented; you must clone and run manually
- No mention of GPU requirements, performance benchmarks, or modern TensorFlow compatibility
Verdict
Grab this if you’re a student or researcher who wants to understand how BiLSTM-CRF works under the hood and doesn’t mind archaeology with TensorFlow 1.x. Skip it if you need production-ready NER or a maintained, pip-installable library.
Frequently asked
- What is scofield7419/sequence-labeling-BiLSTM-CRF?
- A configurable, beginner-friendly BiLSTM-CRF implementation for sequence labeling that hasn't moved on from TensorFlow 1.10.
- Is sequence-labeling-BiLSTM-CRF open source?
- Yes — scofield7419/sequence-labeling-BiLSTM-CRF is open source, released under the GPL-3.0 license.
- What language is sequence-labeling-BiLSTM-CRF written in?
- scofield7419/sequence-labeling-BiLSTM-CRF is primarily written in JavaScript.
- How popular is sequence-labeling-BiLSTM-CRF?
- scofield7419/sequence-labeling-BiLSTM-CRF has 703 stars on GitHub.
- Where can I find sequence-labeling-BiLSTM-CRF?
- scofield7419/sequence-labeling-BiLSTM-CRF is on GitHub at https://github.com/scofield7419/sequence-labeling-BiLSTM-CRF.