sapientinc/HRM-Text
Foundation model pretraining for the price of a gaming PC
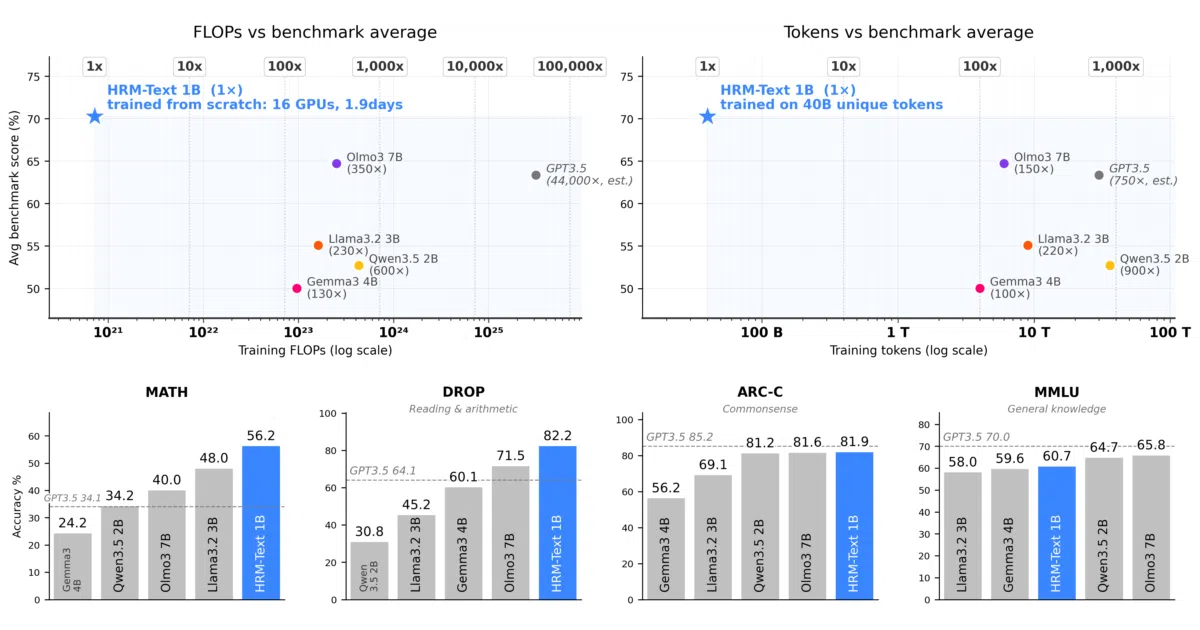
HRM-Text claims to cut pretraining costs by 130–600× compute and 150–900× data, shipping a full 1B-parameter framework with FSDP2, FlashAttention 3, and a hierarchical recurrent architecture.
Velocity · 7d
+9.9
★ / day
Trend
↗accelerating
star history
What it does
HRM-Text is a complete pretraining stack for a 1B-parameter language model built on a hierarchical recurrent architecture (HRM). It includes data sampling, PrefixLM packing, FSDP2 distributed training, evaluation against standard benchmarks, and export to HuggingFace Transformers format. The project targets researchers and engineers who want to pretrain from scratch without cluster-scale budgets.
The interesting bit
The cost claims are the hook: ~$800 for a 0.6B model on 8 H100s in ~50 hours, or ~$1,472 for 1B on 16 H100s in ~46 hours. The architecture itself is a hierarchical recurrent model with “latent space reasoning” and task-completion objectives—details of which are mostly in the linked arXiv paper rather than the README. The training code is notably practical: deterministic stratified sampling into /dev/shm, Dockerized environments, and a two-pass PrefixLM attention path (bidirectional prefix, causal response) implemented in custom FlashAttention kernels.
Key highlights
- Reference benchmarks provided for 0.6B and 1B sizes across GSM8k, MATH, DROP, MMLU, ARC-C, HellaSwag, Winogrande, and BoolQ
- Full SFT pipeline with EMA weight handling and configurable optimizer state reuse
- Multiple architecture baselines included: standard Transformer, Tiny Recursive Model, Universal Transformer, and Recursive Inference Scaling
- Docker image with tested CUDA/PyTorch/FlashAttention 3 stack; Hydra configs for model sizes from 12-layer/1024-dim (B) to 72-layer/1792-dim (XXL)
- Native Transformers model support merged but not yet released; vLLM support in progress
Caveats
- Requires Hopper-class GPUs (H100) because the attention path depends on FlashAttention 3; older hardware is explicitly unsupported
- The “130–600× less compute” and “150–900× less data” claims lack baselines or methodology in the README—you’ll need the arXiv paper for context
- Multi-node checkpointing is shard-per-node; shared storage is strongly recommended to avoid reassembly headaches
Verdict
Worth a look if you’re researching efficient pretraining architectures or need a reproducible, budget-controlled foundation model baseline. Skip it if you need production inference today—vLLM support isn’t ready yet, and the 1B scale is firmly research-tier.
Frequently asked
- What is sapientinc/HRM-Text?
- HRM-Text claims to cut pretraining costs by 130–600× compute and 150–900× data, shipping a full 1B-parameter framework with FSDP2, FlashAttention 3, and a hierarchical recurrent architecture.
- Is HRM-Text open source?
- Yes — sapientinc/HRM-Text is open source, released under the Apache-2.0 license.
- What language is HRM-Text written in?
- sapientinc/HRM-Text is primarily written in Python.
- How popular is HRM-Text?
- sapientinc/HRM-Text has 1.7k stars on GitHub and is currently accelerating.
- Where can I find HRM-Text?
- sapientinc/HRM-Text is on GitHub at https://github.com/sapientinc/HRM-Text.