salesforce/LAVIS
A Unified Front for the Fragmented Vision-Language Zoo
LAVIS bundles the scattered tooling of vision-language research—models, datasets, and evaluation scripts—into a single Python library so researchers can experiment instead of wrangling boilerplate.
Not currently ranked — collecting fresh signals.
star history
What it does
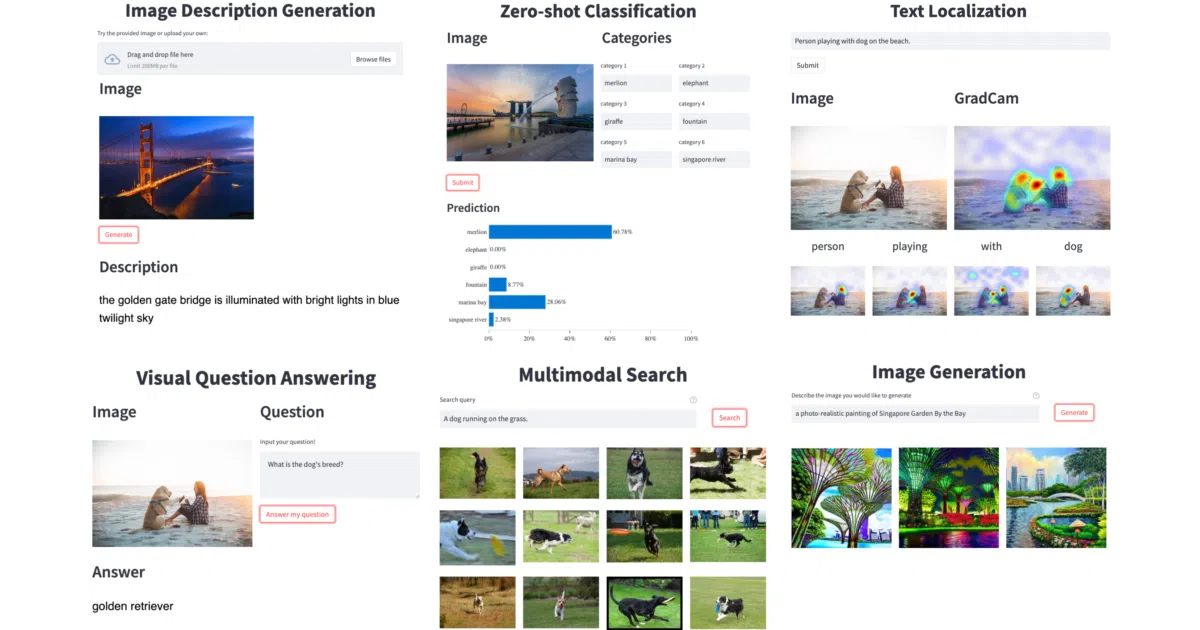
LAVIS is a Python library that corrals a sprawling ecosystem of language-vision models, datasets, and tasks behind one modular interface. It offers off-the-shelf inference, feature extraction, and training recipes for foundation models like BLIP, CLIP, ALBEF, and ALPRO, covering everything from image captioning and visual question answering to video retrieval. The library also includes automatic dataset downloaders to handle the tedious data preparation that usually eats up the first day of any multimodal project.
The interesting bit
Rather than treating each new paper as a separate codebase, LAVIS abstracts them into swappable components—models, preprocessors, and datasets—so you can mix, match, and extend without rewriting training loops. It is essentially an attempt to turn the vision-language research paper trail into a maintainable software dependency.
Key highlights
- Ships with 30+ pretrained model weights and task-specific adaptations, including recent releases like BLIP-2, InstructBLIP, and X-InstructBLIP.
- Supports 10+ tasks—retrieval, captioning, VQA, multimodal classification, and more—across 20+ datasets with automatic downloading scripts.
- Provides a unified feature extraction interface that works across ALBEF, CLIP, BLIP, and ALPRO.
- Includes modular zero-shot VQA frameworks such as PNP-VQA and Img2LLM-VQA, with Img2LLM-VQA specifically reported to beat Flamingo on VQAv2 (61.9 vs. 56.3) without end-to-end training.
- BLIP-2 is reported to beat Flamingo on zero-shot VQAv2 (65.0 vs. 56.3) and zero-shot NoCaps captioning (121.6 vs. 113.2 CIDEr).
Caveats
- The supported-task table still marks text-to-image generation as “[COMING SOON],” even though BLIP-Diffusion was released months earlier, suggesting the documentation may lag behind the code.
- With 10+ tasks, 20+ datasets, and 30+ models, the surface area is vast; finding the right module often means clicking through project-specific pages and Jupyter notebooks.
Verdict
Researchers and engineers who need to benchmark or fine-tune vision-language models without maintaining a dozen separate repos will find LAVIS a genuine time-saver. If you are looking for a minimal, single-purpose inference library, this is probably more toolbox than you need.
Frequently asked
- What is salesforce/LAVIS?
- LAVIS bundles the scattered tooling of vision-language research—models, datasets, and evaluation scripts—into a single Python library so researchers can experiment instead of wrangling boilerplate.
- Is LAVIS open source?
- Yes — salesforce/LAVIS is open source, released under the BSD-3-Clause license.
- What language is LAVIS written in?
- salesforce/LAVIS is primarily written in Jupyter Notebook.
- How popular is LAVIS?
- salesforce/LAVIS has 11.3k stars on GitHub.
- Where can I find LAVIS?
- salesforce/LAVIS is on GitHub at https://github.com/salesforce/LAVIS.