relari-ai/continuous-eval
Stop eyeballing your RAG pipeline
A Python toolkit that breaks LLM evaluation into per-module metrics you can actually test in CI.
Not currently ranked — collecting fresh signals.
star history
What it does
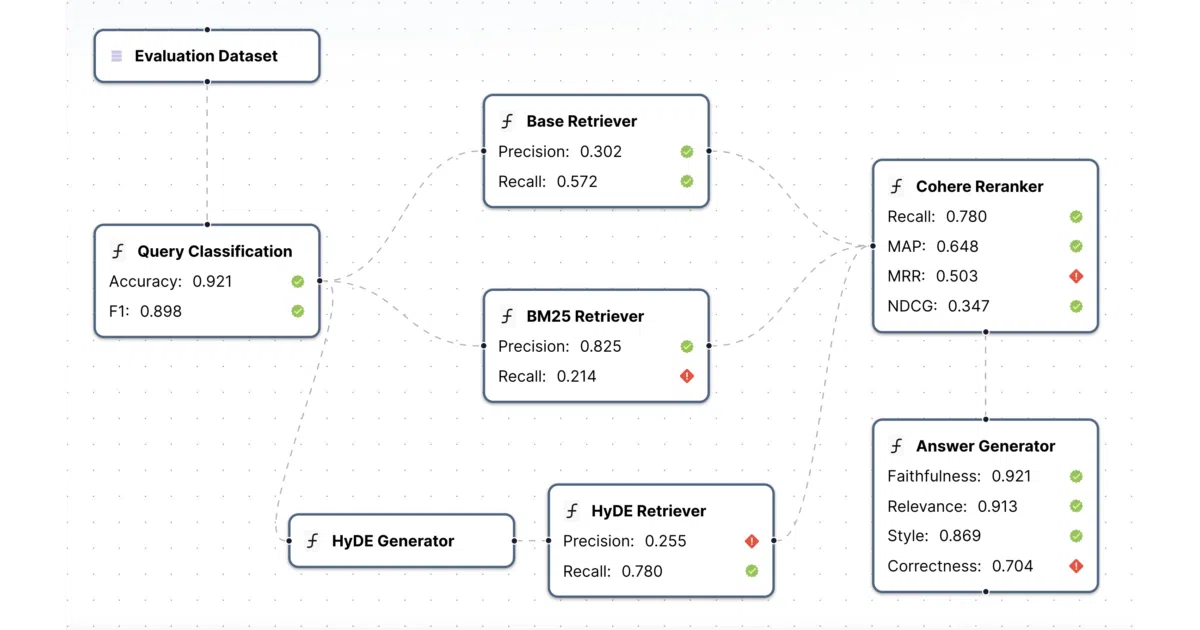
continuous-eval is a Python package for evaluating LLM-powered applications by splitting them into discrete modules—retriever, reranker, generator—and attaching specific metrics to each. It ships with deterministic, semantic, and LLM-as-a-judge metrics for RAG, code generation, classification, and agent tool use. You define a pipeline graph, run evaluation across a dataset, and set threshold-based tests that can fail a build.
The interesting bit
Most evaluation frameworks treat the black box as a single unit. This one forces you to name each stage and extract its outputs explicitly—via ModuleOutput(page_content) or similar—so you can’t pretend a bad retriever is the LLM’s fault. The probabilistic metrics and custom LLM-judge builder are where it gets less conventional than standard accuracy/F1 reporting.
Key highlights
- Modular pipeline evaluation: retriever → reranker → LLM, each with its own metrics and pass/fail tests
- Metric library spans deterministic (Precision/Recall), semantic, and LLM-based judges
CustomMetricclass for spinning up LLM-as-a-Judge evaluators with structured rubricsEvaluationRunnerhandles parallel execution; results aggregate per-module and pipeline-wide- Example datasets and end-to-end examples repo available for bootstrapping
Caveats
- LLM-based metrics require API keys; the README doesn’t specify which providers are supported beyond “at least one”
- Multiprocessing requires wrapping code in
if __name__ == "__main__"guards, which is noted but easy to miss - Telemetry is on by default; you must set
CONTINUOUS_EVAL_DO_NOT_TRACK=trueto disable
Verdict
Worth a look if you’re running RAG or multi-step LLM pipelines in production and want per-stage regression tests. Probably overkill if you’re just spot-checking a single prompt with OpenAI’s evals.
Frequently asked
- What is relari-ai/continuous-eval?
- A Python toolkit that breaks LLM evaluation into per-module metrics you can actually test in CI.
- Is continuous-eval open source?
- Yes — relari-ai/continuous-eval is open source, released under the Apache-2.0 license.
- What language is continuous-eval written in?
- relari-ai/continuous-eval is primarily written in Python.
- How popular is continuous-eval?
- relari-ai/continuous-eval has 516 stars on GitHub.
- Where can I find continuous-eval?
- relari-ai/continuous-eval is on GitHub at https://github.com/relari-ai/continuous-eval.