rdumasia303/deepseek_ocr_app
Vibe-coded OCR app that actually ships PDF export
A weekend-built React wrapper around DeepSeek-OCR that grew into a full document conversion pipeline.
Not currently ranked — collecting fresh signals.
star history
What it does
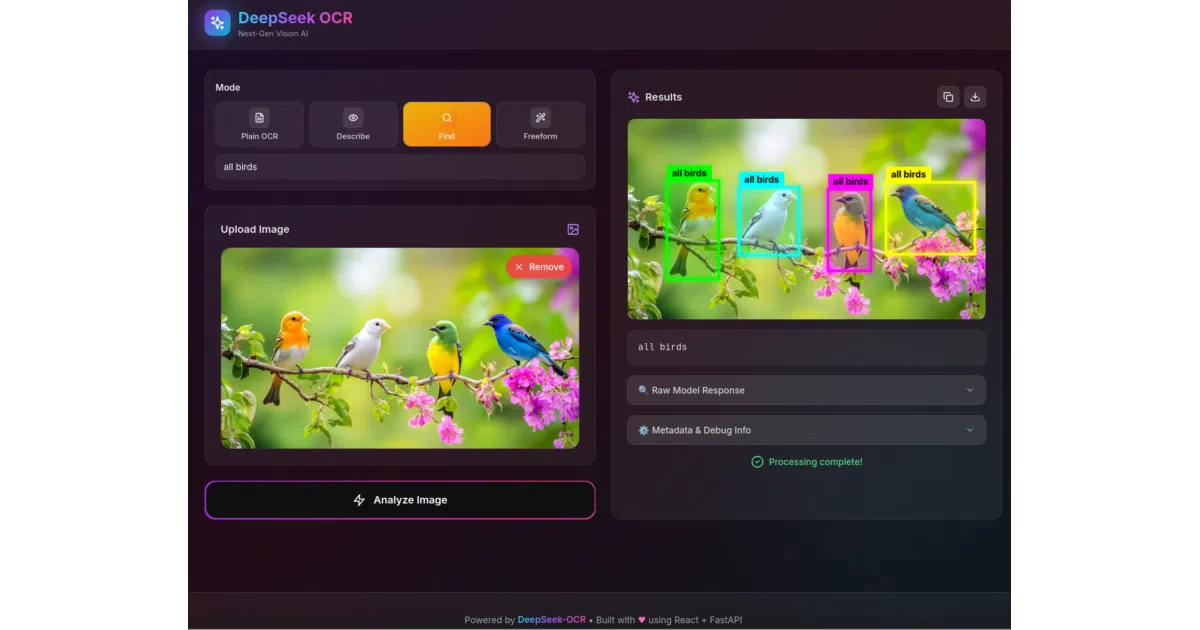
This is a Dockerized web app that wraps DeepSeek’s OCR model in a React frontend. Upload an image or PDF, pick a mode (plain text, describe, find, or freeform prompt), and get structured output. For PDFs, it churns through pages one by one and exports to Markdown, HTML, DOCX, or JSON with progress bars so you know it hasn’t hung.
The interesting bit
The README is unusually honest about its origins—“vibe coded”—yet the feature set has expanded methodically based on community feedback. The v2.2.0 PDF pipeline with format conversion and image extraction feels like a project that started as a demo and accidentally became useful. Also, the author includes a full RTX 5090 driver troubleshooting guide, which is either thorough documentation or a cry for help.
Key highlights
- Dual mode: single-image OCR or multi-page PDF processing up to 100MB
- Four OCR modes: plain extraction, description, term search with bounding boxes, custom prompts
- PDF exports to Markdown, HTML, DOCX, or JSON with embedded image preservation
- Docker Compose setup with NVIDIA GPU support; first run downloads ~5-10GB model weights
- Configurable via
.envfor ports, upload limits, and processing resolution
Caveats
- Requires NVIDIA GPU with 8-12GB+ VRAM; CPU-only operation is not mentioned
- The “Known Issues” section is truncated in the README, so current bugs are unclear
- DOCX export is noted as slower than other formats for large documents
Verdict
Worth a look if you need local, self-hosted OCR with modern model quality and don’t mind feeding it a GPU. Skip it if you’re on Apple Silicon or want a lightweight SaaS alternative; this is firmly a “run it in your basement” tool.
Frequently asked
- What is rdumasia303/deepseek_ocr_app?
- A weekend-built React wrapper around DeepSeek-OCR that grew into a full document conversion pipeline.
- Is deepseek_ocr_app open source?
- Yes — rdumasia303/deepseek_ocr_app is open source, released under the MIT license.
- What language is deepseek_ocr_app written in?
- rdumasia303/deepseek_ocr_app is primarily written in JavaScript.
- How popular is deepseek_ocr_app?
- rdumasia303/deepseek_ocr_app has 1.8k stars on GitHub.
- Where can I find deepseek_ocr_app?
- rdumasia303/deepseek_ocr_app is on GitHub at https://github.com/rdumasia303/deepseek_ocr_app.