ragulpr/wtte-rnn
Predicting when things break, without waiting for them to break
A Keras/TensorFlow framework that turns censored survival data into Weibull-distributed time-to-event forecasts using RNNs.
Not currently ranked — collecting fresh signals.
star history
What it does
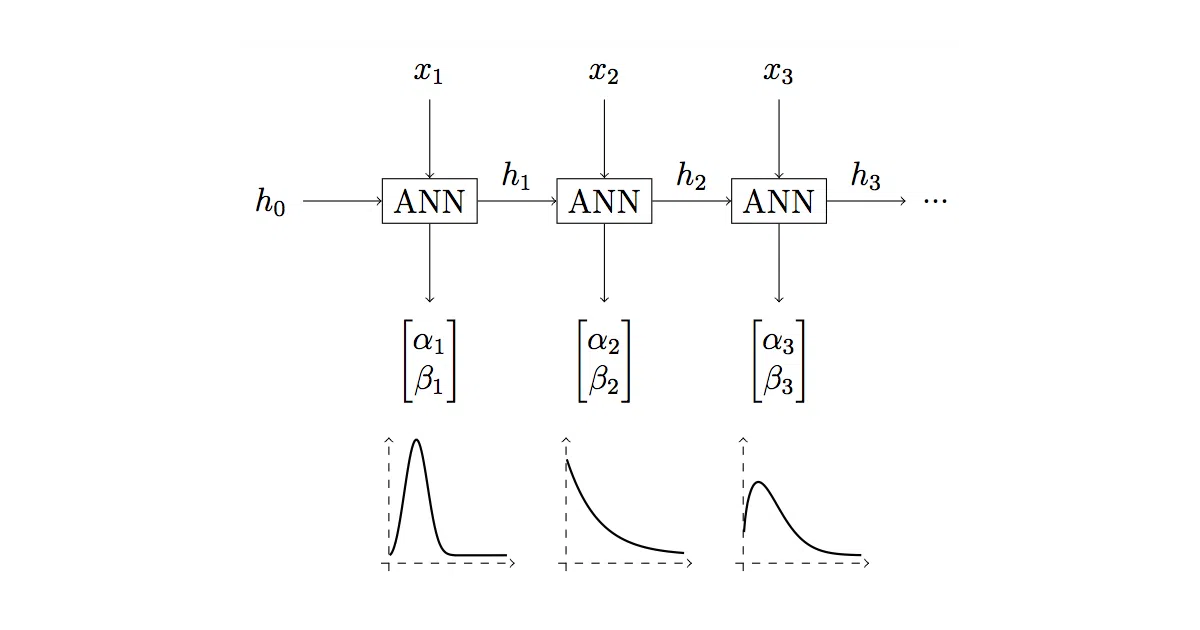
WTTE-RNN tackles a nagging problem in predictive maintenance, churn modeling, and similar domains: you need to predict when an event will happen, but most of your data is “censored” — the event hasn’t occurred yet, so you only know a minimum bound. The framework feeds time-series features through an RNN, outputs parameters of a Weibull distribution, and trains with a custom log-likelihood loss that handles both observed and censored cases correctly.
The interesting bit
Instead of predicting a single point estimate, the model emits two numbers (alpha and beta) that describe a full probability distribution over time-to-event. This gives you both a forecast and a built-in uncertainty measure — the authors note these parameters form a “2-d embedding” you can visualize to see how soon versus how sure each prediction is.
Key highlights
- Implements Weibull output layers and censored-data loss functions for both TensorFlow and Keras (TensorFlow + Theano backends)
- Includes data pipeline utilities for pandas → numpy transformations and censoring indicator calculations
- Provides standard Weibull functions (CDF, PDF, quantile, mean) as building blocks
- Ships with Keras callbacks and helper layers to reduce boilerplate
- Core algorithm distilled to a standalone Jupyter notebook if the full package feels like overkill
- MIT licensed, with a 2016 master’s thesis and blog post explaining the mathematical justification
Caveats
- The project explicitly warns that your censoring mechanism must be independent of your features; otherwise the model learns to predict censoring probability rather than actual time-to-event
- Described as “under development” with a roadmap toward becoming “forkable and easily deployable” — not quite there yet
- Most examples moved to a separate repo (wtte-rnn-examples) to save space
Verdict
Worth a look if you’re doing churn prediction, predictive maintenance, or any survival-analysis problem with sequences and heavy censoring. Skip it if you need a polished, batteries-included production framework — this is still research-grade code with sharp edges around feature engineering and censoring assumptions.
Frequently asked
- What is ragulpr/wtte-rnn?
- A Keras/TensorFlow framework that turns censored survival data into Weibull-distributed time-to-event forecasts using RNNs.
- Is wtte-rnn open source?
- Yes — ragulpr/wtte-rnn is open source, released under the MIT license.
- What language is wtte-rnn written in?
- ragulpr/wtte-rnn is primarily written in Python.
- How popular is wtte-rnn?
- ragulpr/wtte-rnn has 776 stars on GitHub.
- Where can I find wtte-rnn?
- ragulpr/wtte-rnn is on GitHub at https://github.com/ragulpr/wtte-rnn.