pskrunner14/trading-bot
Teaching Atari algorithms to day-trade Google stock
A readable Deep Q-Learning implementation that swaps game screens for price windows and asks whether reinforcement learning can learn to buy low and sell high.
Not currently ranked — collecting fresh signals.
star history
What it does
This is a tutorial-grade stock trading bot built on Deep Q-Learning — the same family of algorithms that learned to play Breakout. It observes an n-day window of normalized price differences, then decides to buy, sell, or hold one share at a time. The reward signal is simply the change in your portfolio value. Training and evaluation scripts are included, plus a Jupyter notebook for visualizing trades.
The interesting bit
The author explicitly keeps the code “as close as possible to the paper, for learning purposes.” That honesty is refreshing: this is pedagogy with a portfolio, not a production system. It also implements three DQN variants — vanilla, fixed target, and Double DQN — while leaving Prioritized Experience Replay and Dueling Networks as unchecked homework.
Key highlights
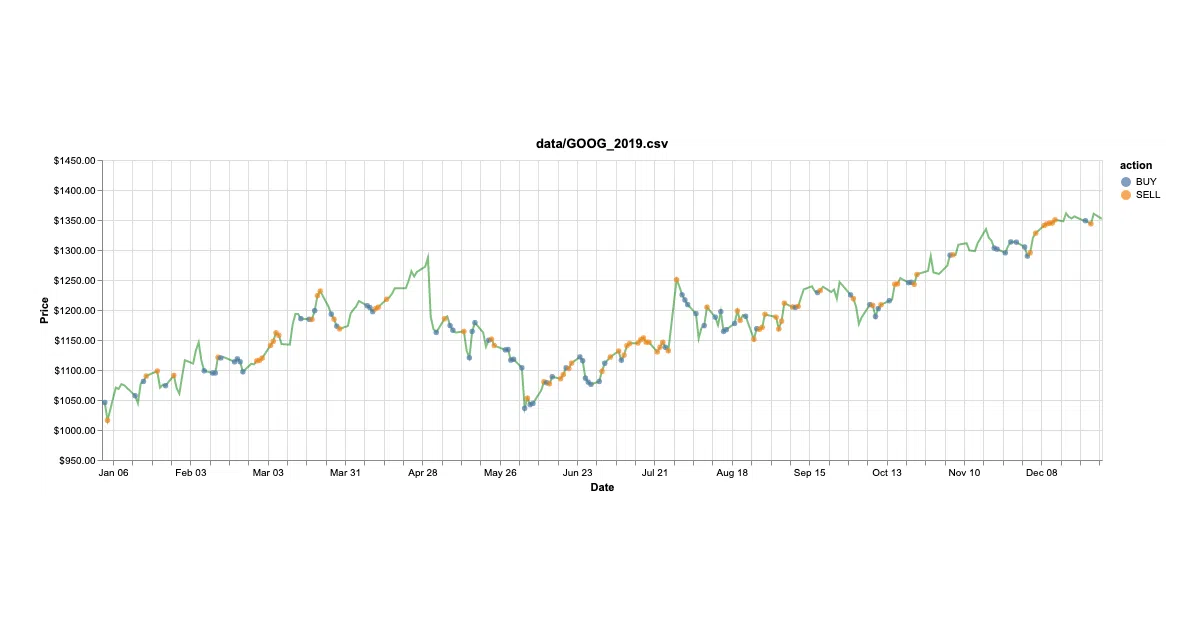
- Trained on GOOG 2010–2017, validated on 2018 ($863.41 profit), tested on 2019 ($1,141.45 profit)
- Three DQN strategies implemented:
dqn,t-dqn, anddouble-dqn - Feature engineering is deliberately simple: sigmoid-normalized differences in adjusted closing price
- CPU training is preferred due to sequential episode structure
- Includes sample data and a visualization notebook
Caveats
- Single-share trades only; position sizing is explicitly out of scope
- Results shown for one stock over a specific bull-market period; generalization is unclear
- The README contains typos (“abserves,” “prefferably”) that suggest limited maintenance
Verdict
Worth a weekend if you’re trying to bridge the gap between DQN papers and something tangible. Skip it if you need risk management, multi-asset portfolios, or any illusion that past profits predict future performance.
Frequently asked
- What is pskrunner14/trading-bot?
- A readable Deep Q-Learning implementation that swaps game screens for price windows and asks whether reinforcement learning can learn to buy low and sell high.
- Is trading-bot open source?
- Yes — pskrunner14/trading-bot is open source, released under the MIT license.
- What language is trading-bot written in?
- pskrunner14/trading-bot is primarily written in Jupyter Notebook.
- How popular is trading-bot?
- pskrunner14/trading-bot has 1.2k stars on GitHub.
- Where can I find trading-bot?
- pskrunner14/trading-bot is on GitHub at https://github.com/pskrunner14/trading-bot.