protectai/llm-guard
A security toolkit that frisks your LLM traffic
It wraps LLM interactions with input and output scanners to block prompt injections, data leaks, toxic content, and other unwanted traffic.
Not currently ranked — collecting fresh signals.
star history
What it does
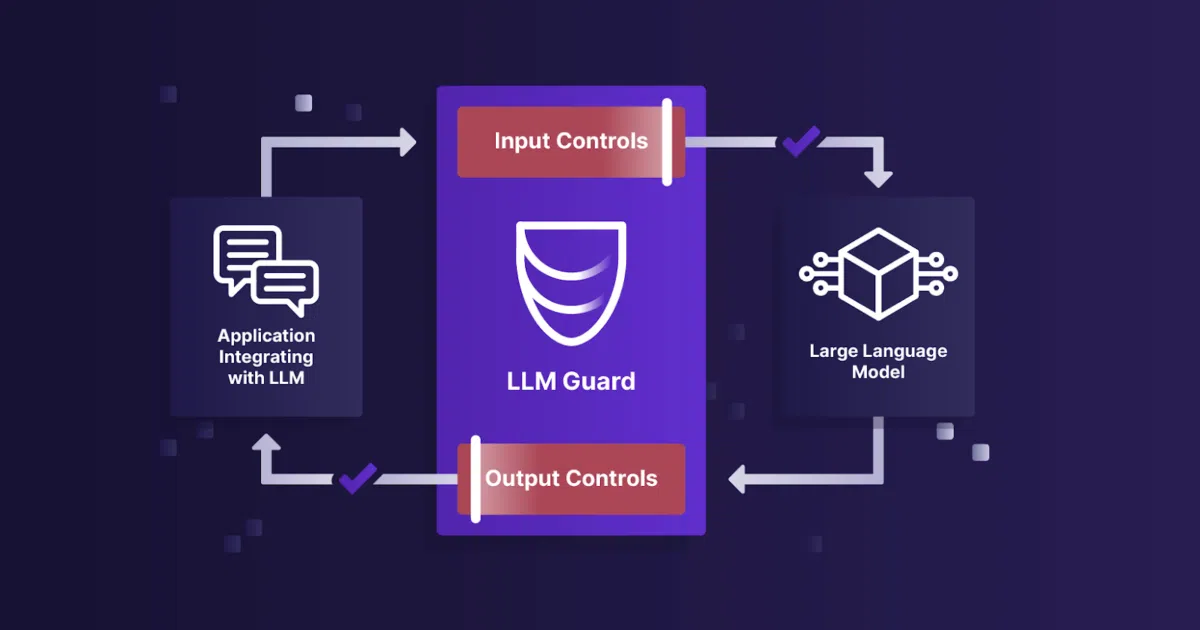
LLM Guard is a Python toolkit that sits between users and a language model, scanning prompts on the way in and completions on the way out. It applies a broad set of checks—ranging from secret detection and prompt-injection resistance to topic blocking and sentiment analysis—to sanitize traffic. Built by Protect AI, it is meant to drop into production as either a library or a standalone API.
The interesting bit
Rather than treating the model as a trust boundary, LLM Guard assumes both the user input and the model output are potentially toxic or leaky. It applies parallel scanner families to both directions—BanCompetitors, Code, Toxicity, and others—and even pairs an Anonymize input stage with a Deanonymize output stage to scrub and later restore sensitive entities.
Key highlights
- Input scanners cover PII anonymization, prompt injection, secrets, invisible text, gibberish, and custom regex bans.
- Output scanners check for bias, malicious URLs, factual consistency, refusal behavior, and sensitive data leaks.
- Several scanners—like
BanTopics,Code, andSentiment—are mirrored across both input and output pipelines. - Designed for production deployment with a limited base dependency set, expanding only when advanced features are used.
Verdict
This is a practical fit for teams that need a broad, policy-heavy filter around commercial or internal LLMs. If your threat model is narrow—say, only prompt injection—a focused, single-purpose tool will likely be lighter.
Frequently asked
- What is protectai/llm-guard?
- It wraps LLM interactions with input and output scanners to block prompt injections, data leaks, toxic content, and other unwanted traffic.
- Is llm-guard open source?
- Yes — protectai/llm-guard is open source, released under the MIT license.
- What language is llm-guard written in?
- protectai/llm-guard is primarily written in Python.
- How popular is llm-guard?
- protectai/llm-guard has 3.2k stars on GitHub.
- Where can I find llm-guard?
- protectai/llm-guard is on GitHub at https://github.com/protectai/llm-guard.