plexe-ai/plexe
AutoML by committee: 14 agents argue over your dataset
Plexe turns a plain-English prompt and a Parquet file into a packaged, deployable ML model via a multi-agent workflow.
Not currently ranked — collecting fresh signals.
star history
What it does
Plexe is a Python tool that builds machine learning models from natural language. You hand it a tabular dataset and an intent like “predict whether a passenger was transported,” and it returns a trained model, metrics, and a self-contained deployment package. It wraps the process in a CLI and Python API, with Docker images and optional PySpark support.
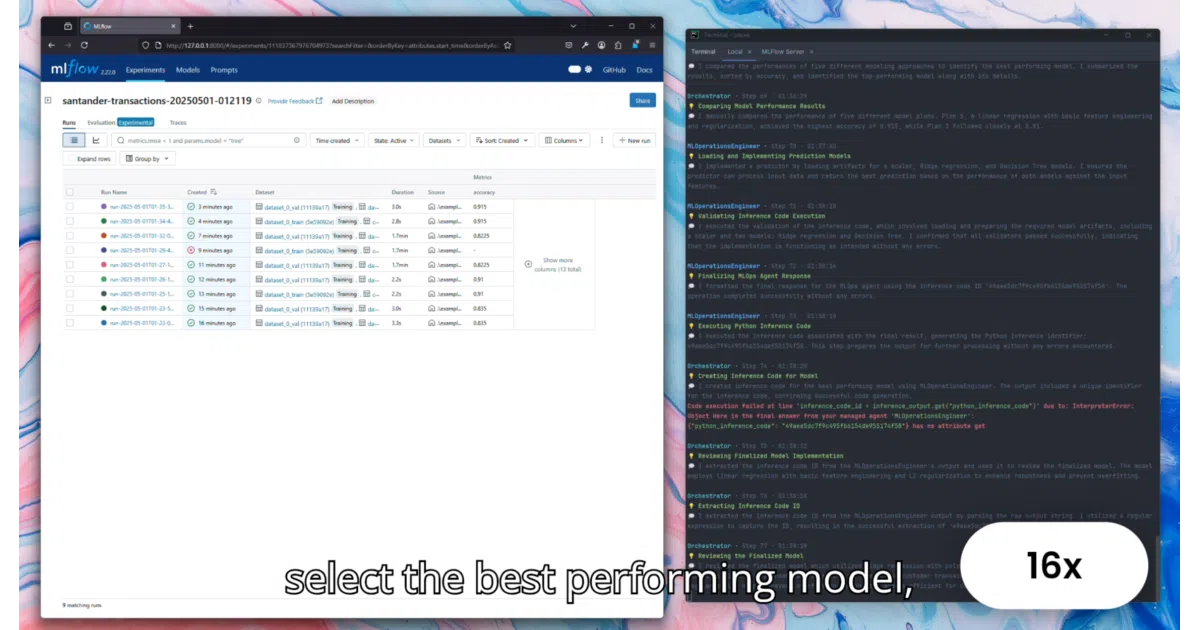
The interesting bit
The project delegates the work across 14 specialized agents in a 6-phase pipeline—data analysis, metric selection, hypothesis-driven model search, evaluation, and packaging. You can route different agents to different LLM providers via LiteLLM, so your feature engineer might run on Claude while the model definer runs on a local Llama 3. The output is deliberately dependency-free: a model.tar.gz with pickles, schemas, and a README you can deploy without Plexe installed.
Key highlights
- Supports XGBoost, CatBoost, LightGBM, Keras, and PyTorch for tabular data
- Self-contained model package at
work_dir/model/with artifacts, schemas, and inference code - Docker images with PySpark and Java pre-installed; Databricks Connect target available
- YAML config for LLM routing, search iterations, and Spark tuning
- Streamlit dashboard for visualizing experiment results and search trees
WorkflowIntegrationinterface for plugging in custom storage or tracking
Caveats
- Requires Python 3.10–3.12; no support outside that range
- Only actively tested with OpenAI and Anthropic models; other LiteLLM providers are “should work” territory
- Needs both
OPENAI_API_KEYandANTHROPIC_API_KEYexported even if you plan to route elsewhere
Verdict
Worth a look if you want to automate tabular ML pipelines and don’t mind LLM agents doing the architecture decisions. Skip it if you need deep custom modeling, non-tabular data, or guaranteed reproducibility without API costs.
Frequently asked
- What is plexe-ai/plexe?
- Plexe turns a plain-English prompt and a Parquet file into a packaged, deployable ML model via a multi-agent workflow.
- Is plexe open source?
- Yes — plexe-ai/plexe is open source, released under the Apache-2.0 license.
- What language is plexe written in?
- plexe-ai/plexe is primarily written in Python.
- How popular is plexe?
- plexe-ai/plexe has 2.6k stars on GitHub.
- Where can I find plexe?
- plexe-ai/plexe is on GitHub at https://github.com/plexe-ai/plexe.