platonai/Browser4
A Kotlin browser engine that speaks SQL to scrapers and English to LLMs
Browser4 is a coroutine-safe automation layer built for AI agents that need to browse, extract, and scale without drowning in token costs.
Not currently ranked — collecting fresh signals.
star history
What it does Browser4 wraps Chrome DevTools Protocol in a Kotlin coroutine layer and exposes three interfaces: a Rust CLI for scripting, a Kotlin API for fine-grained control, and natural-language agents for LLM-driven tasks. It handles navigation, DOM snapshots, data extraction, and parallel session management. The headline trick is X-SQL — a SQL-like dialect that mixes CSS selectors, XPath, and LLM calls in a single query against a loaded page.
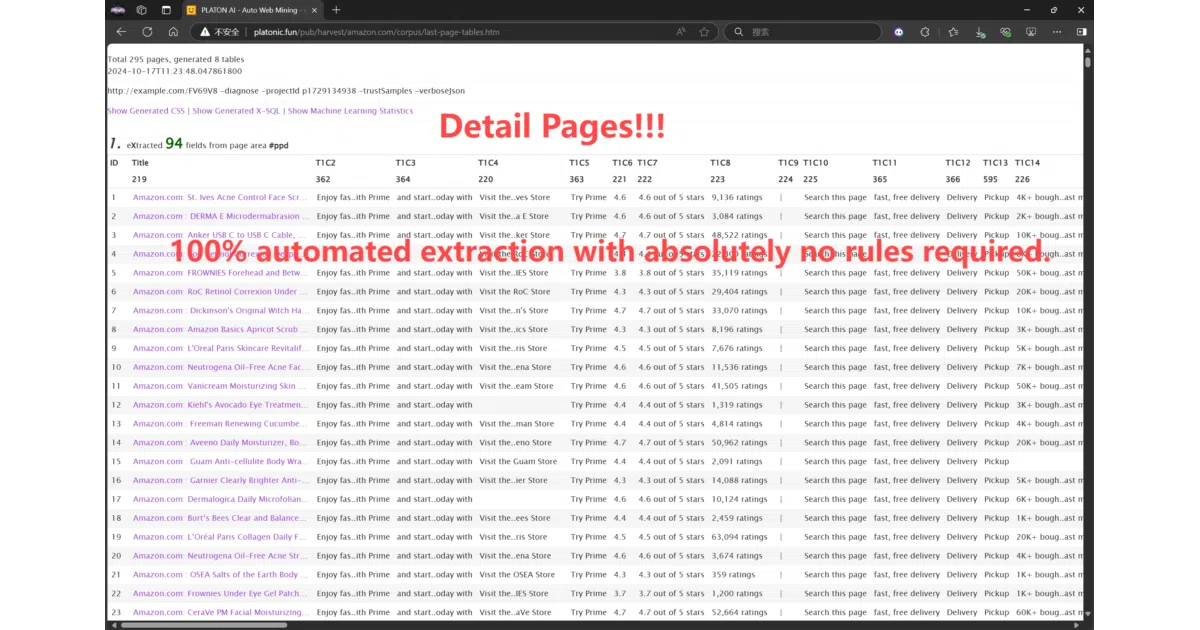
The interesting bit The project tries to dodge the LLM tax at scale. It pairs token-heavy extraction with an ML-based “Auto Extraction” mode that learns page structures locally and claims 95%+ field discovery without API calls. That hybrid — deterministic selectors plus optional LLM enrichment — is the pitch for running 100k+ complex pages per day on modest hardware.
Key highlights
- X-SQL queries:
select dom_first_text(dom, '#price') ... from load_and_select('url', 'body')mixes selectors and LLM calls in one statement. - Coroutine-native CDP: Direct Chrome DevTools Protocol control with parallel session management and resource blocking (e.g., drop images for speed).
- Agent layers: Natural-language agents for end-to-end tasks, plus low-level
snapshot/click/extractAPIs for precise control. - CLI with SKILL hooks: Rust CLI installs via npm and exposes a Playwright-compatible command set that LLM agents can invoke through a SKILL.md contract.
- Modular architecture: Core engine, agentic layer, REST wrapper, and orchestration modules split into separate Maven modules.
Caveats
- Auto Extraction is not in-repo yet: The ML-based extraction lives in the companion project PulsarRPAPro; native Browser4 API exposure is “planned.”
- Performance claims are indicative: The “100k–200k pages/day” figure is labeled a target, not a benchmark, in the feature matrix.
- Anti-bot features marked experimental: “Advanced anti-bot tec[h]” is listed as experimental and the README truncates mid-word there.
Verdict Worth a look if you’re building Kotlin-based scraping pipelines or want a structured query layer over browser automation. Skip it if you need a mature, fully open-source ML extraction engine today — the auto-extraction piece is still gated behind a companion project and a star-count threshold.
Frequently asked
- What is platonai/Browser4?
- Browser4 is a coroutine-safe automation layer built for AI agents that need to browse, extract, and scale without drowning in token costs.
- Is Browser4 open source?
- Yes — platonai/Browser4 is open source, released under the Apache-2.0 license.
- What language is Browser4 written in?
- platonai/Browser4 is primarily written in Kotlin.
- How popular is Browser4?
- platonai/Browser4 has 1.1k stars on GitHub.
- Where can I find Browser4?
- platonai/Browser4 is on GitHub at https://github.com/platonai/Browser4.