pinecone-io/canopy
Pinecone's RAG framework is now a museum piece
An open-source RAG toolkit that got you chatting with documents in three CLI commands—until Pinecone stopped maintaining it.
Not currently ranked — collecting fresh signals.
star history
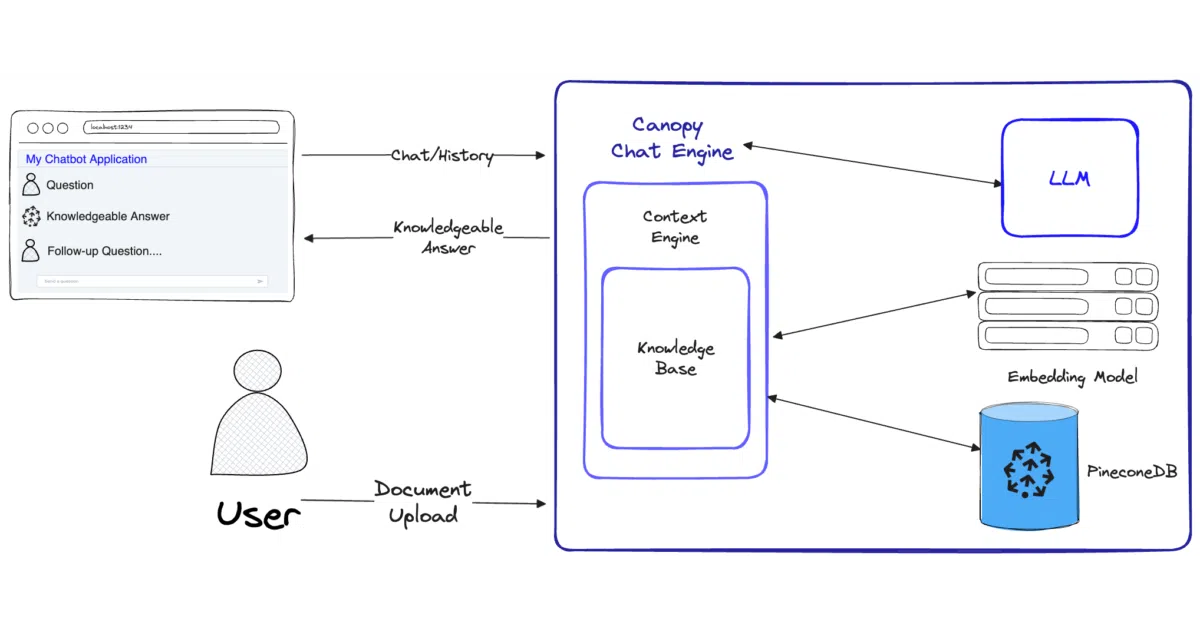
What it does
Canopy is a Python framework that wires up the full RAG pipeline: chunking documents, embedding them into Pinecone (or Qdrant), retrieving relevant chunks, and feeding them to an LLM as context. It ships as a library (ChatEngine, ContextEngine, KnowledgeBase), a FastAPI server, and a CLI that lets you spin up an index, upload files, and chat from the terminal.
The interesting bit
The CLI includes a side-by-side mode that compares RAG-augmented answers against raw LLM responses—useful for debugging whether your retrieval is actually helping or just adding latency. The server exposes a standard REST API with Swagger UI, so you can bolt it onto an existing chat frontend without writing glue code.
Key highlights
- Three CLI commands to go from zero to chatting with your documents (
canopy new,canopy upsert,canopy start) - Supports multiple LLM and embedding providers: OpenAI, Azure OpenAI, Cohere, Anyscale, OctoAI, Jina AI
- Optional Qdrant backend if you want to skip Pinecone
- Built-in chat history management and query optimization
- FastAPI server with Gunicorn/Uvicorn for production deployment
Caveats
- No longer maintained. Pinecone explicitly abandoned the project and points users to their commercial “Pinecone Assistant” instead
- Hard dependency on Pinecone for the default path; Qdrant support exists but feels secondary
- README is vague on chunking strategy, embedding dimensions, and how query optimization actually works
Verdict
Good for learning RAG plumbing or forking into something custom, but don’t start a production app on it today. If you want a supported path, Pinecone has made their commercial alternative very clear.
Frequently asked
- What is pinecone-io/canopy?
- An open-source RAG toolkit that got you chatting with documents in three CLI commands—until Pinecone stopped maintaining it.
- Is canopy open source?
- Yes — pinecone-io/canopy is open source, released under the Apache-2.0 license.
- What language is canopy written in?
- pinecone-io/canopy is primarily written in Python.
- How popular is canopy?
- pinecone-io/canopy has 1k stars on GitHub.
- Where can I find canopy?
- pinecone-io/canopy is on GitHub at https://github.com/pinecone-io/canopy.